


Being able to infer human bodies in images automatically has opened avenues for an array of real-life applications.
Everyone, in one way or another, has used these technologies. If you've used Zoom (and almost everyone has in the past two years 😒) and played around a bit with filters, or if you like augmented reality apps like DreamSnap, or perhaps you have security cameras at home that alert you when they detect humans. Then, you've used computer vision.
To achieve all of the above, computer vision has expanded into sub-branches you might have heard of: Image segmentation and classification, object detection, tracking, human pose estimation, among others.
With all this jargon and terminology, it's easy to get lost. This blog post aims to bring clarity while expanding a bit more on body detection through computer vision.
First, we'll go back to basics and develop the concept of computer vision and the branches that comprise it. Then we'll dive into body detection with computer vision, its different approaches, their practical applications, and enumerate the most relevant models in each category, considering benchmark, pros, and cons.
What's Computer Vision
The desire to have a machine or robot think like a human being, to build what is now known as Artificial Intelligence, has been there since before the first computer existed; think Mary Shelley's Frankenstein or Ovid's Pygmalion and his ivory statue.
But if you think about it, what would those creations be if they couldn't see? Sight is a critical human sense; we can process about 36,000 bits of information each hour through our eyes. So if we wanted computers to think and reason like human beings, them having the ability to see seems logical. Enter, computer vision.
A sub-study or branch of AI, it aims to provide machines with the capacity not only to see but also to look. Its aim is for machines to extract valuable information from digital videos and images and use it to gain a deeper understanding, to think and act as we do.

It's no news; we're producing an enormous amount of data every single day, and it's worth noting that a significant percentage of it consists of images and videos (about three billion photos are shared every day online). Furthermore, almost every single human being carries a cell phone with them everywhere, which means they take a camera at all times and use it constantly. Moreover, the quality of images and videos is improving daily, making it easier to process them. It's only natural that machines take advantage of that vast pool of information.
Engineers have been using computer vision algorithms to automate tasks, like understanding a handwritten letter, identifying cars through their license plate, ensuring humans use face masks, and detecting missing objects on shelves.
And although it's broadly studied, it generates a lot of enthusiasm among people (the computer vision market is expected to reach $48.6 billion by 2022, according to Forbes), resulting in tremendous advances over a small amount of time. The hype is also partly due to companies such as Google, IBM, Microsoft, and Facebook sharing their research through open-source work.
How it works
Computer vision relies basically on two Machine Learning concepts to interpret and understand images and videos:
- Deep Learning: A Machine Learning method based on artificial neural networks made up of multiple layers that can process unstructured data in its raw form of text or images.
- Convolutional Neural Network: Deep learning is often comprised of neural networks. Inspired by the human brain, it's a general-purpose layered function that can solve a problem by learning from a labeled dataset.
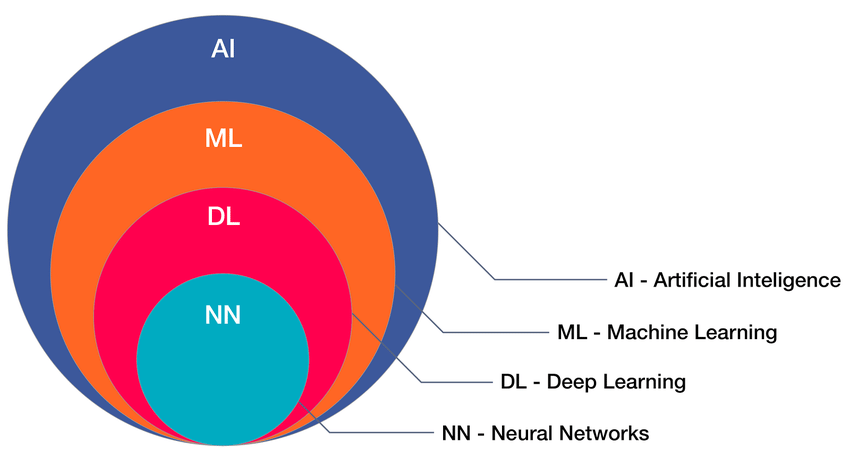
Most standard computer vision applications already have a trained deep learning model that engineers can use out of the box. For more complex solutions, engineers need to optimize models or even design a model from scratch, which requires training the algorithm to make the predictions, detect events, etc., properly.
Notice that creating and training a Convolutional Neural Network from scratch requires solid machine learning skillsets and considerable quantities of data. Still, luckily there are plenty of already trained models for human detection, pose estimation, and segmentation, the most used human detection algorithms.
Computer Vision Techniques
Replicating human sight through a computer can be achieved in several ways depending on your objectives and the type of data you want to obtain. These are the most common techniques that, combined or by themselves, have proven to be effective and are widely used.
Image Segmentation
It's believed the first thing our brain tends to do when presented with an image is to single out the different objects that comprise it. Segmentation models do this by dividing the image into several parts called segments or objects. These segments are composed of various pixels sharing some common attributes: color, intensity, texture, optical focus. Once grouped, each pixel gets a class assigned. Putting together those pixels that contain the information needed to be processed saves the model time by ruling out regions of the image with no value. There are two types of image segmentation:
- Semantic segmentation: the process in which pixels are segmented according to their class.
- Instance Segmentation: the process that takes part when the image has multiple objects. In which case the objects are masked with different colors and treated as separate entities, all the pixels associated with each object are given the same color.
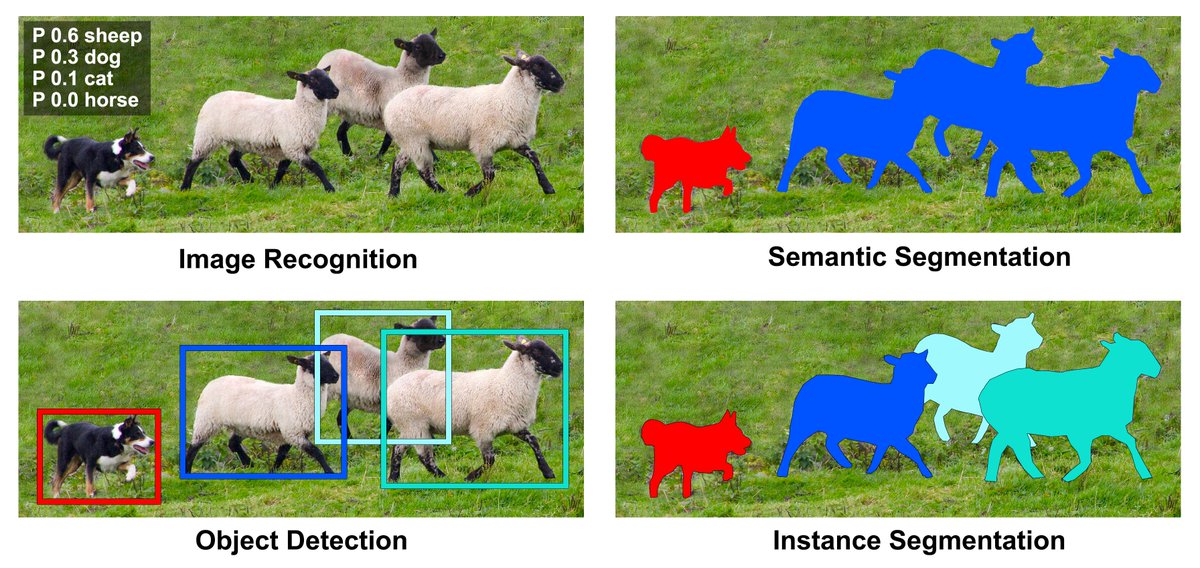
Image Classification
Image classification occurs when a specific image (comprised of one object) is assigned a class (i.e., a tag). It allows the model to look at a picture and determine whether the object is a human being, a dog, a cat, a plant, etc.
To train the models in applying these predefined categories (dog, person, flower), you can access an array of different datasets containing classified images.
If the image contains more than one object, classification is also possible through a multi-level classifier.
Object Detection
Once you classify all the objects in the image, the next step would be to locate the objects within the image. And that's where object detection comes in. The system can now identify where all the objects are in relation to each other. Think of object detection like image localization plus classification for all the objects an image contains.
After applying an OD model, your image should look like the one below: a bounding box around each object in the image with its corresponding class and a score to reflect the confidence on the accuracy of the detection.
It used to take 20 seconds to process an image and determine where an object was. Now it's about 1000 times faster (20 milliseconds per image) in a couple of years, thanks to contributions such as open-sourced YOLO (bounding boxes and class probabilities simultaneously). This means object detection can be made in real-time.
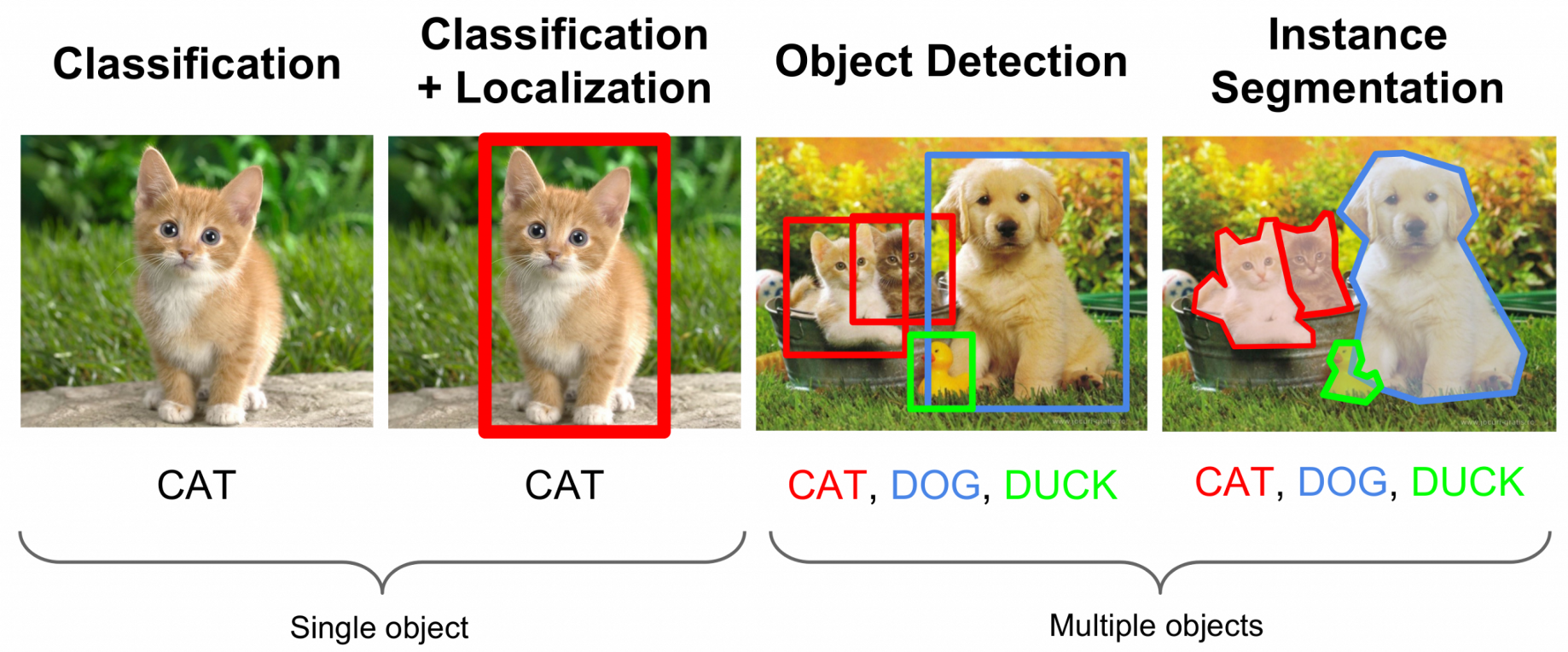
Object Tracking
So what happens when the object we need to identify is not on a static image but a video? That is, how can we keep track of a thing that's moving? This would be the case if, for example, we wanted to identify a particular person or persons in a security camera footage. That's when object tracking comes in to save the day! This process follows a certain object/s over time in the video, and it keeps track of it (or them) through each frame.
Tracking works with objects that change in size, shape, and position depending on the angle they are being captured from if they are moving, the light, etc. Tracking algorithms also contain motion estimation models that understand the dynamic behaviors of objects to predict their trajectory, i.e., the areas where the object is likely to be found in later frames.
Pose Estimation
Tracking works with objects that change in size, shape, and position depending on the angle they are being captured from if they are moving, the light, etc. Tracking algorithms also contain motion estimation models that understand the dynamic behaviors of objects to predict their trajectory, i.e., the areas where the object is likely to be found in later frames.

Image or video streaming can be used as the model input. Its output provides information about each body keypoint's position, generally in the form of a 2D space coordinate and a confidence score between 0 and 1.
There've been several performance improvements around pose estimation. For instance, the Google team is actively working on the MoveNet project, which provides real-time pose estimation data apart from having an outstanding accuracy rate/score.
Body Detection using Computer Vision
One of the most popular applications for computer vision has been to detect humans: their faces, expressions, postures, movements, or their mere presence. Body detection is increasingly becoming part of our daily lives, from face recognition to unlock phones to Amazon's "Just Walk Out" stores. The advances in computer vision are facilitating this progress.
Highly driven by the desire to make interactions between humans and machines better, the analysis of natural environments doesn't come without its challenges. Human detection is a relatively new field, and the rapid changes in scenes involving humans and the different positions they adopt are also part of the hurdle. Below we'll discuss implementing the different Computer Vision techniques we discussed earlier to detect human beings: when to use one over the other, the different learning models, and its benchmarks
Human detection
What's human detection?
Human detection is a subset of Object Detection (OD). Essentially, any OD system that can detect the class "Human" can be considered a Human Detection System.
When to use human detection?
These are the algorithms to use if you need to detect the presence of people within a space. They can detect multiple people, whether they are still or in movement, or at different distances from the camera and each other.
Practical applications of human detection
Autonomous Driving: One of the most well-known applications that has gained more hype in recent years is self-driving cars. Object detection is critical for the concept of autonomous driving to work, as it needs to identify pedestrians among other objects to avoid disasters.
Public Spaces: Human detection is also used to help public spaces in more ways than one
- For video surveillance: detection of people in restricted areas, suicide prevention, monitor remote locations, or homeland security, among others.
- Pedestrian detection: this increasing trend, has become popular with the coming of smart cities: intelligent transportation systems, traffic management, and law enforcement are just some of the applications for pedestrian detection.
Covid has changed our lives radically, and it has also brought about a new set of worries when it comes to having more than one person in a public space. Computer vision has been there to reach a helping hand through applications like workspace/room occupancy. With the world slowly opening up, seating or visitor capacity and room occupancy have also come part of the everyday vocabulary. From public spectacles to museums and offices, keeping an eye on the compliance of protocols is essential.
Tools like lanthorn.ai have helped this process by making the task simpler and automatic by reusing existing OD models such as mobilenet_ssd and yolov3 to resolve other complex tasks like guaranteeing the social distancing in your building or the occupancy rates.
Retail stores have also been applying CV to improve their customer's experience by gathering information of their movements within the store, where they spend more time, where they gaze directs to the most, etc. This helps them understand their customers/users better and has also become key in marketing and sales strategies, layout optimization, and overall efficiency of the stores.

Popular deep learning models
As explained earlier, object detection (so, human detection) performs two tasks: finding several objects and classifying every single one plus estimating their size with a bounding box. Models can do these tasks in one or two steps depending on the speed and level of accuracy you need:
- Two-stage object detectors: it tends to be more accurate but slower. First, it proposes/estimates a region for the object using conventional CV methods or deep networks. Then it classifies the object based on features extracted from the said region with bounding box regression.
- One-stage object detectors: faster (suitable for real-time applications) but not as accurate as the two-stage method. They skip the regional proposal step and go directly to object classification. This makes them less accurate when it comes to irregular-shaped or small objects.
When choosing a model, there are two main metrics to consider: accuracy and inference time.
Accuracy is measured through mean average precision (mAP), which combines two requirements for the mode: finding all the objects in an image, and checking if the class assigned is correct, and is measured through a percentage (the higher the percentage, the most accurate the model).
Inference time is how long it takes to execute the algorithm, and it's typically measured in frames per second (FPS) or milliseconds (ms). The lower the time it takes, the better and the most useful it is for real-time applications. This metric is key if you are looking to use these models in products.
If you are building a product, it's important to check how complex is to integrate the chosen model with the technology stack you're using. Sometimes, the state-of-the-art models published in papers are experiments that only work in some specific scenarios.
For example, Yolo's models are used in several products (like Lanthorn) because they are stable solutions that give you good results and perform well on some devices (27 fps in GTX 1660S). However, if you need real-time object detection in devices with fewer resources (such as Jetson or Coral ones), maybe it's better to use MobileNet SSD (https://arxiv.org/abs/1704.04861) .
Human pose estimation
What's human pose estimation?
Human pose estimation is, as the name hints, a branch of pose estimation. Unlike object detection (which is normally applied to other things besides human detection), human pose detection is the most common application of this branch.
When to use human pose estimation?
Human pose estimation is used to build a human body representation (a pose) from visual input data. Features and key points are extracted from this data and represented through human body modeling.
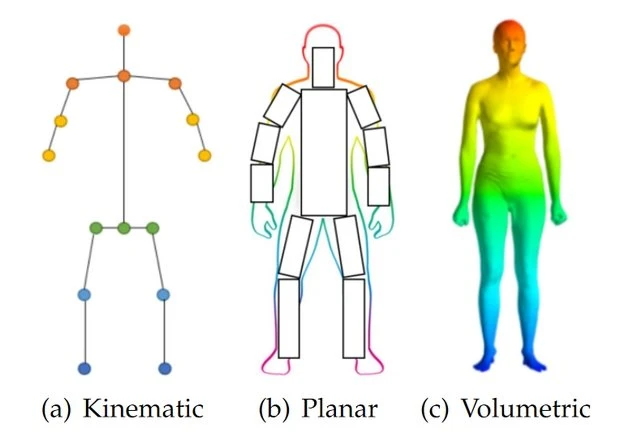
Usually, these algorithms demand more CPU resources than a simple human detection, so it's essential to use them only if body positions are vital to the solution. Most algorithms return skeleton-based information in 2d coordinates, which provides "x" and "y" coordinates for each body keypoint, or 3d coordinates: "x", "y" and "z" coordinates.
Pose estimation models face some difficulties as it primarily deals with people not only moving (and getting in and out of frame) but with different types of events that dramatically alter the appearance and position of key body points: different clothes and backgrounds, diverse lightning and several kinds of weather, motion blur in videos, defocus, visual obstructions, etc.
Practical applications of pose estimation
Lately, pose estimation has been gaining popularity throughout different industries, such as entertainment (think augmented reality games like Pokemon Go, Virtual Reality headsets, Xbox's motion tracking), health (human fall detections), and fitness (the trendy fitness mirrors, or exercise apps).
This last application has undergone a significant increase in popularity in the last couple of years as people have begun to exercise from home. An excellent example of such an application is a fitness app we're working on. Made using MoveNet (that looks for 17 key points in a person's body), it represents a great example of pose estimation done for mobile, with the bonus of pose embedding. Hence, the model knows how the user should do specific workouts and suggests corrections. It can also count repetitions of the exercise the user's doing and track the user's progress.
Technical approaches to pose estimation
Pose estimation can be categorized into two groups: single-person pose estimation and multi-person pose estimation. Most practical applications of pose estimation are made in environments with several people, making the job more difficult for algorithms. There are two ways to go around multi-person applications: top-down and bottom-up algorithms. Top-down methods run a person detector, put bounding boxes around them, and then estimate the body joints of each box; they usually perform better. Bottom-up approaches tend to estimate the keypoint first and then group them into a unique pose.

Popular deep learning models
In terms of datasets, although there are several (FLIC, MPII, AI Challenger, Buffy, VOC), the right one always depends on the use case you have in mind. For example, the OpenPifPaf model supports detecting poses of multiple people simultaneously and runs at 25 FPS on a GTX 1080Ti. On the other hand if you need more speed and only care about detecting poses for 1 person at a time, you can use MoveNet which runs at 30 FPS on much smaller devices like Android mobile phones.
Benchmarks and scores
Pose estimation models are measured according to the number of key points they can detect accurately through Average Precision. Paperswithcode came up with a ranking of several of the models mentioned previously and ranked them based on their score of Average Precision for large objects (APL). According to it, HRNet has the higher score, closely followed by AlphaPose.
Human body segmentation
What's human body segmentation?
Like image segmentation, human body or person segmentation groups pixels within the human body according to a specific body part. Body segmentation models segment the body from the background (it can also be done along with segmenting the body parts), then detect the body's boundaries, mask them, and classify them according to the part they belong to (arm, leg, etc.).
When to use it
Body segmentation can be used for many things by itself, but its use to improve performance on tasks like pose recovery or gesture recognition cannot be undermined. And although it has its challenges, some of which we mentioned previously, like changes in body pose, shape, clothes, etc., it has evolved considerably in the last couple of years, and its application has been incrementing in several industries.

Practical applications
The health industry has greatly benefited from image segmentation to process biomedical images such as x rays, tomographies, MRIs, PET scans, or ultrasounds. Although doctors do a manual visual analysis, variation in interpretation, fatigue errors, image quality, inexperience, etc., can lead to wrong diagnostics. By automating this task, an extra layer of accuracy is added to the overall analysis.
Extracting face features is becoming increasingly popular for verifying identities; the most widespread use is to unlock mobile phones or access apps within them. It's also used for video surveillance, as well as homeland security.
Once again, retail applies state-of-the-art technology, this time for clothes classification, retexturing and virtual try-on. Person segmentation enables the potential customer to try new clothes and even change their style (color, texture, etc.), and it's also good for classifying apparel (pants, tops, dresses).
Photography editing is also much easier with segmentation. Not only its easier to separate the body from the background (hello Zoom once again), but it's also simpler to make edits to the human body. For example, if you want to edit just one aspect of the human face (eyes, lips, hair, skin color) using another image as style input (see image below).

Popular deep learning models
Most segmentation models are measured against by their mean Intersection over Union (mIoU). Intersection over union is an evaluation metric that measures the accuracy of an object detector on a dataset by comparing the location of the predicted bounding box (the one the detector came up with) with the one of the ground-truth bounding box (the hand-labeled one). It's scored from 0 to 1; the closer to 1, the more accurate the model.
Some of the most popular ones are Mask R-CNN (simple to train and easy to use), CDCL (Cross-Domain Complementary Learning), SCHO (good for single, multiple, and video segmentation), and WSHP (which transfers human body parts to raw images by exploiting their anatomical similarity).
Conclusion
Although advancing at an incredible rate, there's still much to do and explore within computer vision. Retail, healthcare, security, and entertainment are just some of the industries benefiting from this technology, but the possibilities are endless. There's still a long way to go; after all, replicating the human vision and the interpretation the brain does of images it's no easy task (since we are not even 100% sure of how the brain does it). There's still a lot of fertile ground in computer vision, and any business, project, or industry can benefit from it.
There's also much to learn, and, luckily, many people are willing to share new models and discoveries they do on the field. Having so many models to choose from can also be a challenge, but, as we saw in the post, it will come down to the one that fits the best with your use case.
If you're interested in learning more about how it might fit in your plans, don't hesitate to reach out!
Sources
https://www.ibm.com/topics/computer-vision
https://www.ibm.com/cloud/learn/machine-learning
https://www.ibm.com/cloud/blog/ai-vs-machine-learning-vs-deep-learning-vs-neural-networks
https://tryolabs.com/resources/introductory-guide-computer-vision/
https://www.tensorflow.org/lite/examples/object_detection/overview
https://pjreddie.com/darknet/yolo/
https://cv-tricks.com/object-tracking/quick-guide-mdnet-goturn-rolo/
https://www.archives-ouvertes.fr/hal-01571292/document
https://developers.google.com/machine-learning/glossary
https://viso.ai/deep-learning/object-detection/
https://neuralet.com/article/human-pose-estimation-with-deep-learning-part-i/
https://towardsdatascience.com/introduction-to-object-detection-model-evaluation-3a789220a9bf
https://paperswithcode.com/paper/squeezedet-unified-small-low-power-fully/review/

