

Machine Learning
Distilling Intelligence: How to Train a Small LLM Without Sacrificing Quality

Is it possible to get the reasoning of a +100B parameter model packed into a 400MB binary that runs on a phone? Yes. In this post I'll show you how I integrated the reasoning capabilities of a frontier model like Gemini 3.1 Pro into a small model like Qwen with just 500 million parameters, using an SFT (Supervised Fine-Tuning) strategy on real-world data. The result? Minimal latency, zero cost, and complete privacy.
1. The Bias of "AI Obesity"
In agent development, technical inertia pushes us to always use the most powerful model available: "For any problem, the natural instinct is to reach for GPT-5.5 or Claude 4.6 Sonnet." However, in production environments (and even more so in HealthTech), this approach runs into three hard walls:
-
Latency: For a chat interface, waiting 5–10 seconds for Time To First Token (TTFT) destroys the user experience.
-
Privacy: In healthcare, privacy isn't a "feature" it's a legal requirement. Sending patient data to third-party clouds complicates compliance with regulations like HIPAA or GDPR.
-
Scalability and Vendor Lock-in: Building on top of third-party APIs ties your product to a critical dependency on external providers (vendor lock-in). At high volumes, variable operational costs become prohibitive, threatening the long-term financial viability of the agent. Local execution transforms a marginal per-token cost into a fixed, controllable infrastructure cost.
The necessary insight: We don't need a model that can write COBOL and explain quantum physics for a task that specifically requires structuring medical information under a protocol. This is where Distillation comes in.
2. The Concept: Model Distillation (Teacher-Student)
Distillation isn't just "copying" the large model. It's a process where a Teacher Model, in our case Gemini, generates high-quality "rationales" or responses that serve as labels for training a much smaller Student Model.
The Use Case: Redi (Medical Preparation Agent)
Our agent helps patients synthesize their condition before seeing a doctor, using the SBAR framework (Situation, Background, Assessment, Recommendation).
Infrastructure Evolution
We moved from a complex architecture on AWS Bedrock (with VPCs, Private Links, and fixed management costs) to a model that can live in a lightweight container or even on the edge.
3. The Data Strategy (Supervised Fine-Tuning): Building the "Golden Dataset"
The success of fine-tuning depends not on quantity, but on information density. Many developers fail when they try to fine-tune on thousands of noisy examples. We bet on quality: 327 perfect examples.
The Data Pipeline (Data Engineering)
Before training, we transformed logs from real (anonymized) conversations into a training dataset. The flow was:
- Observability: Capturing real AI-User interactions.
- Cleaning: Chronological ordering by
conversation_idand role normalization (human->user). - Rationalization Filtering: This is where the magic happens. We used the "Teacher" to clean the noise.
The Distillation Prompt (The "Brain" of the Process)
We didn't ask the small model to learn from raw logs. We used a rewriting prompt to have Gemini act as an expert curator.
This is the script we used to generate our JSONL compatible with apply_chat_template:
import json
from typing import Optional, Dict
def distill_conversation(json_line: str) -> Optional[Dict]:
"""
Transforms a raw conversation into a 'Gold Standard' example
using a Teacher LLM to align the output with the SBAR framework.
"""
base_prompt = """
You are an expert in Data Engineering for LLMs and a specialist in SBAR medical communication.
MISSION:
You will receive a real conversation between a user and the assistant 'Redi'.
Your task is to rewrite the assistant's response to make it a perfect training example.
GOLDEN RULES:
1. SBAR Framework: The response MUST include: Situation, Background, Assessment, Recommendation.
2. No Diagnosing: Validate symptoms and prepare the consultation, but never give a medical diagnosis.
3. Consistency: Empathetic, professional, and structured tone.
4. Quality Filter: If the conversation is trivial (e.g., just a 'hello'), respond with 'SKIP'.
OUTPUT: Return EXCLUSIVELY a JSON with the structure:
{"messages": [{"role": "system", "content": "..."}, {"role": "user", "content": "..."}, {"role": "assistant", "content": "..."}]}
"""
try:
# Call to the Teacher model (Gemini 3.1 Pro)
full_prompt = f"{base_prompt}\n\nORIGINAL CONVERSATION:\n{json_line}"
response = model.generate_content(full_prompt)
text = response.text.strip()
if "SKIP" in text: return None
# Clean markdown if the model responds with code blocks
clean_json = text.replace("```json", "").replace("```", "").strip()
return json.loads(clean_json)
except Exception as e:
print(f"Distillation error: {e}")
return NoneAn example of the resulting training record:
{
"messages": [
{"role": "system", "content": "You are a medical intake assistant."},
{"role": "user", "content": "I have frequent headaches."},
{"role": "assistant", "content": "How long have you been experiencing them?"}
]
}Why is this approach superior?
- Strict Alignment: We force the small model to learn the SBAR format from day one.
- Hallucination Elimination: By using real data rewritten by a superior model, the small model learns safe and accurate response patterns.
- Cost-Effective: We only pay for Gemini API calls during the dataset creation phase, just once.
4. Technical Implementation: From Theory to 95 Seconds of Training
To train a model faster than it takes to make a cup of coffee, we used an optimized "heavy artillery" stack: Unsloth + QLoRA.
The Heart of the Pipeline: QLoRA and Adapters
We don't update all 500 million parameters of the model. That would be inefficient. Instead, we use LoRA (Low-Rank Adaptation).
The technical intuition: Think of the base model as a general medicine textbook. Instead of rewriting the whole book (full fine-tuning), we add "sticky notes" (Adapters) on the key pages that teach it to structure information in SBAR format. Mathematically, we factorize the weight update matrix into two much smaller matrices (A and B), drastically reducing the computational load.
Training Configuration
These are the "magic numbers" that allowed the model to converge rapidly:
| Parameter | Value |
|---|---|
| Model | Qwen 2.5 0.5B (4-bit quantization) |
| LoRA Rank (r) | 16 |
| Learning Rate | 2e-4 |
| Effective Batch Size | 8 |
| Training Time | ~95 seconds (single RTX 3090) |
Responses-Only Training
One of the keys to our precision was enabling --train_responses_only. We didn't want the model to learn how to imitate how the user speaks, but exclusively how the medical assistant should respond. This concentrates all the gradient on the output policy.
Code Snippet for Reproduction
from unsloth import FastLanguageModel
from trl import SFTTrainer
from unsloth.chat_templates import train_on_responses_only
# Load the model in 4-bit to democratize training (runs on 8GB GPUs)
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Qwen2.5-0.5B-Instruct-bnb-4bit",
max_seq_length = 2048,
load_in_4bit = True,
)
# Insert adapters into the Attention and MLP modules
model = FastLanguageModel.get_peft_model(
model,
r = 16,
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],
lora_alpha = 16,
lora_dropout = 0,
)5. Results: How Good Is a 0.5B Model?
The biggest risk with fine-tuning on such small models is "catastrophic forgetting" or the model simply learning to repeat the format without understanding the underlying logic. To avoid confirmation bias, we subjected the model to a two-level evaluation process.
A. Internal Metrics (Optimization Health)
First, we verified that the learning process was stable. We weren't just looking for the loss to drop, we wanted it to drop smoothly, indicating the model is generalizing patterns rather than noisily memorizing.
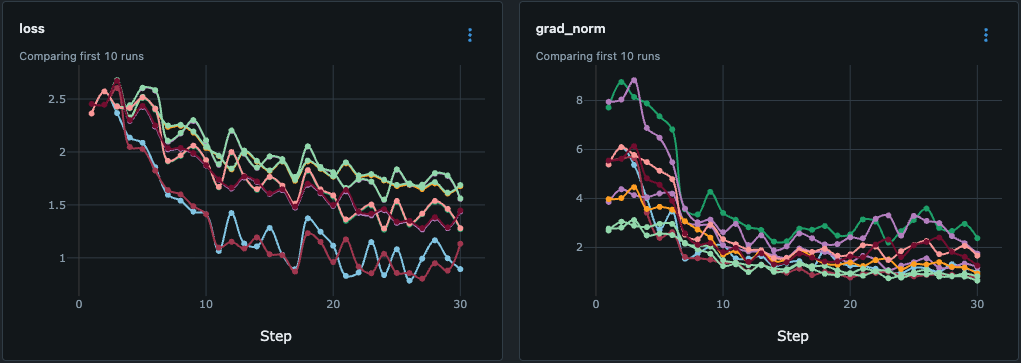
Evidence: As shown in the MLflow logs (image above), we achieved a 46% reduction in loss with a stable gradient. This confirms that the "Student" (Qwen) has healthily absorbed the structure from the "Teacher" (Gemini).
B. External Benchmark (HealthBench)
For the test, we didn't use data that the model had already seen. We used a test battery based on the HealthBench framework (inspired by OpenAI and Google protocols for healthcare).
Why this benchmark? Because it doesn't just measure "whether the sentence sounds nice." It measures critical dimensions:
- Clinical Accuracy: Is the medical information correct?
- Safety: Does it avoid giving dangerous or incorrect diagnoses?
- Key Omissions: Did it forget to ask about allergies or key medical history?
- SBAR Compliance: Did it follow the professional communication structure?
We compared three models under equal conditions: the original Qwen 2.5 0.5B, our Qwen FT (Fine-Tuned) version, and the "upper bound" (market reference), Claude 4.6 Sonnet.
| Metric | Qwen 2.5 (Base) | Qwen 2.5 (FT) | Claude 4.6 (Cloud) |
|---|---|---|---|
| Clinical Accuracy | 5.90 | 6.06 | 6.42 |
| Safety | 8.54 | 8.74 | 9.82 |
| Conciseness | 7.02 | 7.56 | 8.04 |
| Latency (t/s) | 267 | 100 | 46 |
The big surprise: Although Claude remains the king of pure reasoning, our model with just 0.5B parameters managed to outperform the base model on every quality metric, and came dangerously close to frontier-model performance on the specific SBAR task.
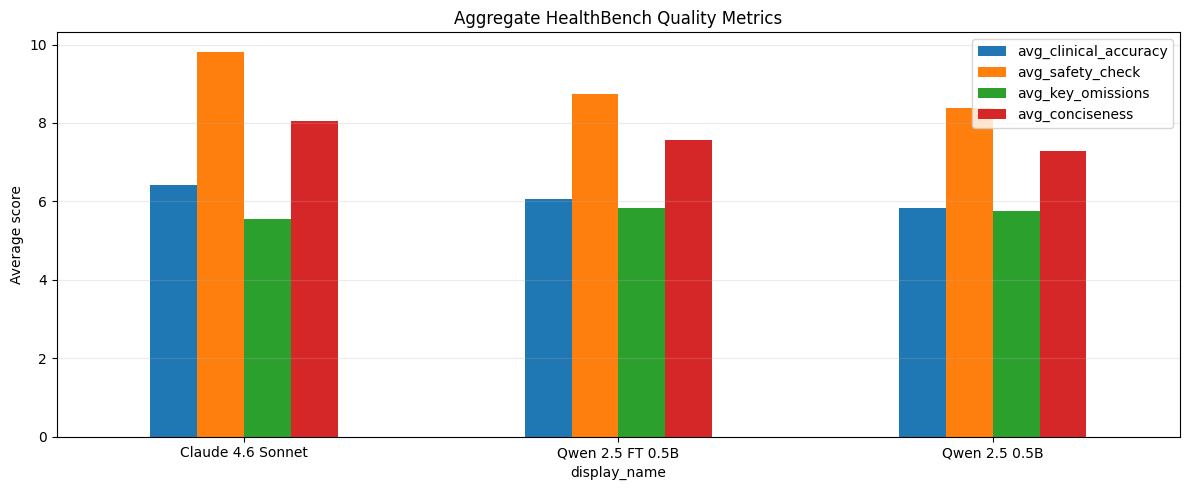
1. The Quality Leap (Baseline vs FT)
The fine-tuned model doesn't just "speak better" it is safer and more precise than its base version:
- Clinical Accuracy: Increased from 5.90 to 6.06.
- Safety Check: Improved from 8.54 to 8.74 (critical in healthcare).
- Conciseness: Jumped from 7.02 to 7.56, eliminating the unnecessary "verbosity" common in generic LLMs.
2. The Latency and Cost Victory
This is where the SLM (Small Language Model) shines against giants like Claude 4.6 Sonnet:
| Metric | Claude 4.6 Sonnet (Cloud) | Qwen 2.5 FT (Local) |
|---|---|---|
| Tokens per Second | 46.74 t/s | 100.47 t/s (2x faster) |
| Average Latency | ~23 seconds | ~10 seconds |
| Cost per Token | $$$ | $0.00 |
| Privacy | Data travels to Cloud | 100% On-Device |
Inference Conclusion
The resulting model weighs just 400MB in GGUF format (Q4_K_M quantization). This means it can run locally in Ollama, in a lightweight Docker container, or even on a Raspberry Pi, while maintaining a level of medical reasoning that competes with models 200 times larger.
6. From Training to Reality: Local Inference with Ollama
Having a trained model in a PyTorch adapter is great for experimentation, but production requires portability. This is where we transform our work into something any user can run with a single command.
The Export Process (GGUF)
Using Unsloth to convert the fine-tuned model to GGUF format. This format not only packages the model and adapter into a single file, but also allows aggressive quantization without losing precision.
- Chosen format: Q4_K_M (4-bit).
- Final weight: ~400 MB.
How to Integrate It in Ollama in 3 Steps
1. Create a Modelfile: This file tells Ollama how the model should behave and what its "personality" is.
FROM ./qwen-redi-sft.gguf
PARAMETER temperature 0.3
SYSTEM """You are Redi, a medical assistant specialized in consultation preparation.
Your goal is to gather patient information using strictly the SBAR format."""2. Build the model:
ollama create redi-med -f Modelfile3. Run it:
ollama run redi-medResult: Inference with a latency of <50ms per token on a standard CPU, with no dedicated GPU required.
7. Final Thoughts: Quality > Quantity
This experiment shows that the era of "giant models for everything" is giving way to the era of specialized models.
Key Takeaways
- The "Golden Dataset" is real: 300 examples curated by a "Teacher" model (Gemini 3.1 Pro) are worth more than 100,000 rows of raw logs.
- SLMs are the future of the Edge: A well-trained 500M parameter model can handle niche tasks with surprising effectiveness, eliminating API bills and privacy concerns.
- Distillation is accessible: Thanks to tools like Unsloth, the cost of training these models has dropped from thousands of dollars to just a few cents of electricity.
What's Next?
If you're a developer, my recommendation is to stop seeing LLMs as a black-box API and start seeing them as infrastructure you can own. Follow us on our social media for more content like this.
References and Further Reading
- Hu, J. J., et al. (2021). LoRA: Low-Rank Adaptation of Large Language Models.
- Dettmers, T., et al. (2023). QLoRA: Efficient Finetuning of Quantized LLMs.
- Hsieh, C. Y., et al. (2023). Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data.
- Yang, A., et al. (2024). Qwen2.5 Technical Report.
- OpenAI (2024). HealthBench: A benchmark for evaluating LLMs in healthcare.

