


At Xmartlabs, our machine learning team set out to develop an innovative ML product last year. After careful consideration and collaboration with our Design team, we decided to focus on building a sign language practice assist system instead of a full-fledged sign language translator. Read more about our thought process (including the product definition and market research) in this blog post by our design team.
Our goal was to create a real-time model that could run on a client's device, in the cloud or a combination of both. This blog post will explore our efforts to develop an embedding model for sign language practice, trained on the large WLASL dataset (a US sign language dataset). The key feature of our model is its ability to be applied to other sign languages and datasets without the need for fine-tuning. We will also showcase its versatility by highlighting various use cases and future works.
Background — Previous work on Sign Language Recognition
Previous research has explored Sign Language recognition, including video-based models and keypoint-based models. Here we discuss some of the most notable studies in the field
Video-based models
Video-based models take a video as input and generate action or sign classification scores. They are known for their accuracy but tend to be heavier and slower than other models.
A popular approach to this type of model is the use of recurrent networks or 3D convolutions. The paper "Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset" by DeepMind introduces Inflated 3D ConvNets, which have been shown to be more accurate than other 3D ConvNets or LSTM + CNN models.
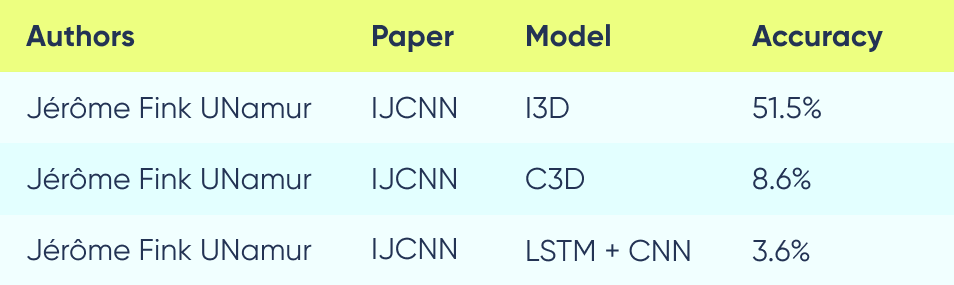
Keypoints-based models
Boháček and Hrúz presented the SPOTER model for Sign Language Recognition in 2022, outlined in their paper "Sign Pose-based Transformer for Word-level Sign Language Recognition". Unlike video-based models, SPOTER uses body pose keypoints as input. Although its accuracy may not match models like I3D, it offers the advantage of being smaller and faster, making it suitable for certain applications (such as our use case). The code for SPOTER is open-source, enabling further development.
In September 2022, the same authors presented a new paper, announcing significant improvements to the SPOTER model. The improvement was achieved through the use of a better pose estimator, which led to SPOTER setting a new SOTA score for sign language classification on the WLASL benchmark.

Methodology - Our Approach to Develop a Real-Time Sign Language Model
We required a model that could perform in real-time, either on mobile devices or browsers. We also wanted a model that would allow for fast iteration and faster training. The image-to-pose problem has been effectively addressed by various models, so we opted to use one of these models and work with a smaller model that takes keypoints as input. Some of these models have the added advantage of being able to run in real-time on edge devices.
This led us to use SPOTER, which has the following advantages over models based on video/image input:
- Smaller size → Better to deploy on edge devices
- Fewer parameters to train → Easier and quicker to train
- Much lower inference time (11x slower on average reference)
By separating the pose estimation and sign classification into two parts, we were able to adopt a hybrid approach. The pose estimation part can be run on mobile devices or browsers. In contrast, the sign classification part can be run on a server, resulting in improved privacy, reduced network bandwidth usage, and lower server load.
However, the original SPOTER model did not suit our use case as we aimed to allow users to practice signs and search for similar signs, not to translate sign language. Additionally, we wanted to train the model for Uruguayan Sign Language, for which we lacked a large dataset.
To allow for the training of embedding vectors for each input sequence of pose keypoints, we modified the output layer of the model. This involved changing the loss function to a Triplet Loss and keeping the output dense layer size equal to the size of the embedding vectors. This modification allowed us to train the model on the WLASL dataset and apply it to unseen sign classes. As a result, our model became a zero-shot embedding model capable of working on new datasets not seen during training, as demonstrated in the Results section.
SPOTER:
SPOTER embeddings:
_(1).gif)
We also used Mediapipe’s Holistic Body Pose model, based on BlazePose (as mentioned in “Spoter using MediaPipe”) to create the keypoints dataset. This improved our results considerably compared to using the keypoints dataset provided in the SPOTER repository, which was created with Apple’s Vision framework.
To evaluate the effectiveness of our model in clustering different sign classes, we used the Silhouette score as a metric. A high Silhouette score indicates that vectors of the same class are closer to each other than to vectors of other classes.
We also implemented a custom triplet selection mechanism and hard triplet mining in the following way:
- We select a pre-batch of $B*M$ input sequences, where $B$ is the batch size and $M$ is the number of batches to compute simultaneously.
- We compute current embeddings for these input sequences.
- We create $M$ batches by grouping together:
- Input sequences of the same class and far away from each other
- Input sequences of different classes and close to each other
- We compute the forward pass for a whole batch and then compute the triplet loss for all hard triplets in that batch.
- We loop 5 times over the batches in a pre-batch to reduce the time impact of grouping these batches.
Results
In this section, we will present the results we obtained with our model.
Silhouette score
We used the silhouette score to measure how well the clusters are defined during the training step. Silhouette's score will be high (close to 1) when all clusters of different classes are well separated from each other, and it will be low (close to -1) for the opposite. Our best model reached 0.7 on the train set and 0.1 on validation.
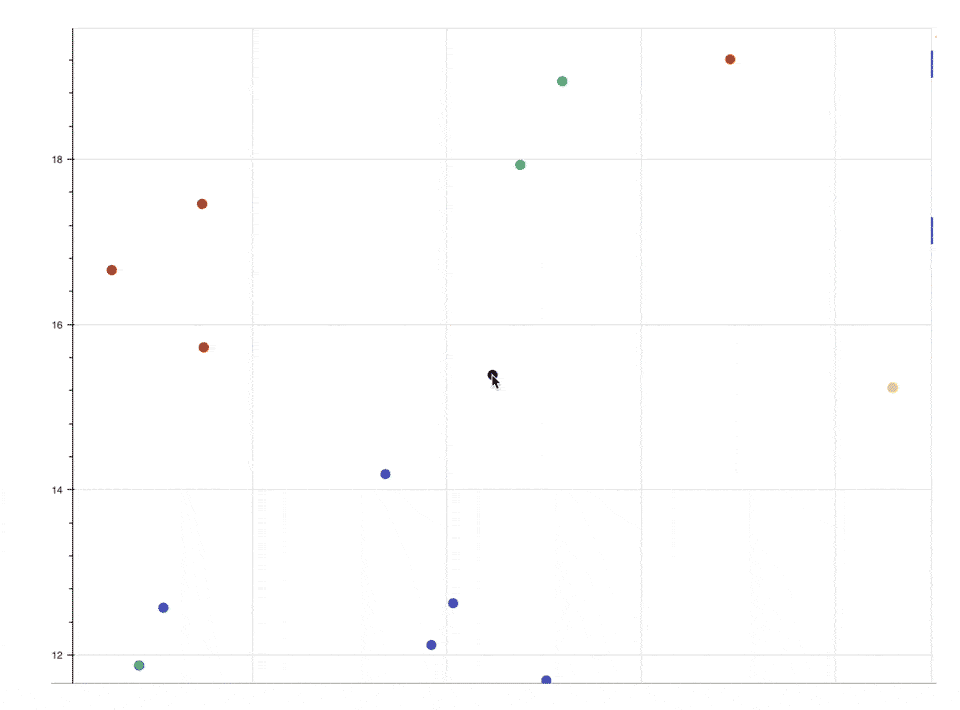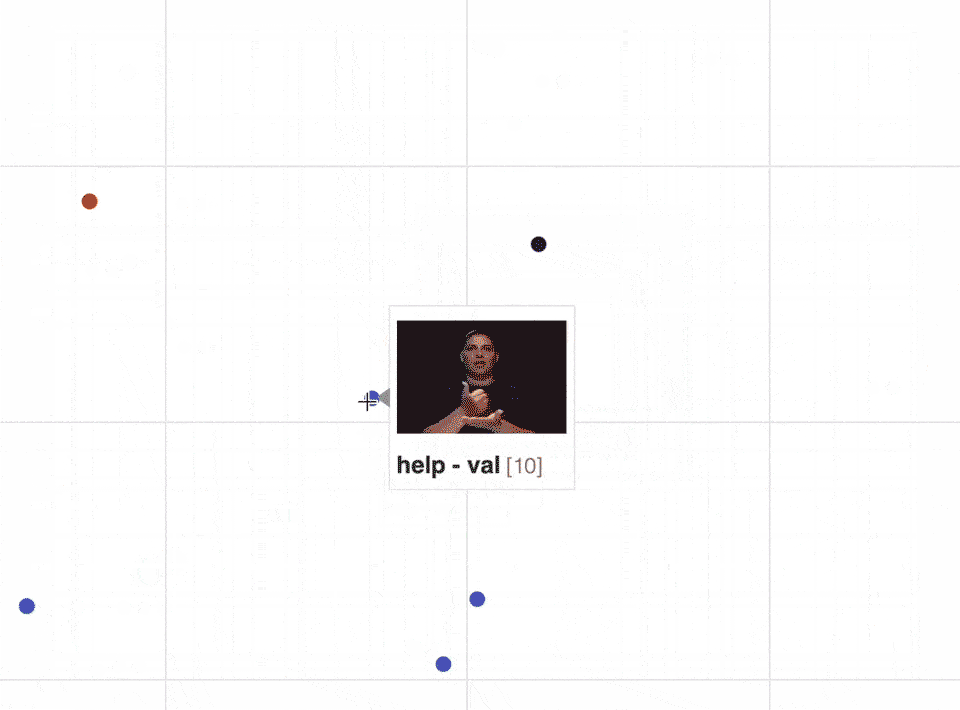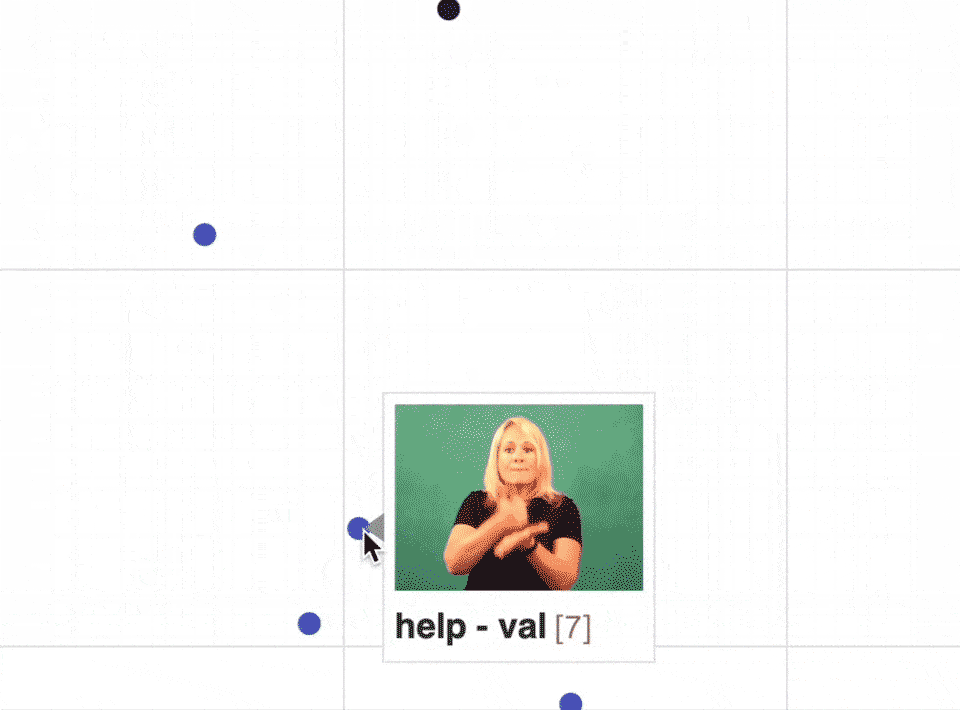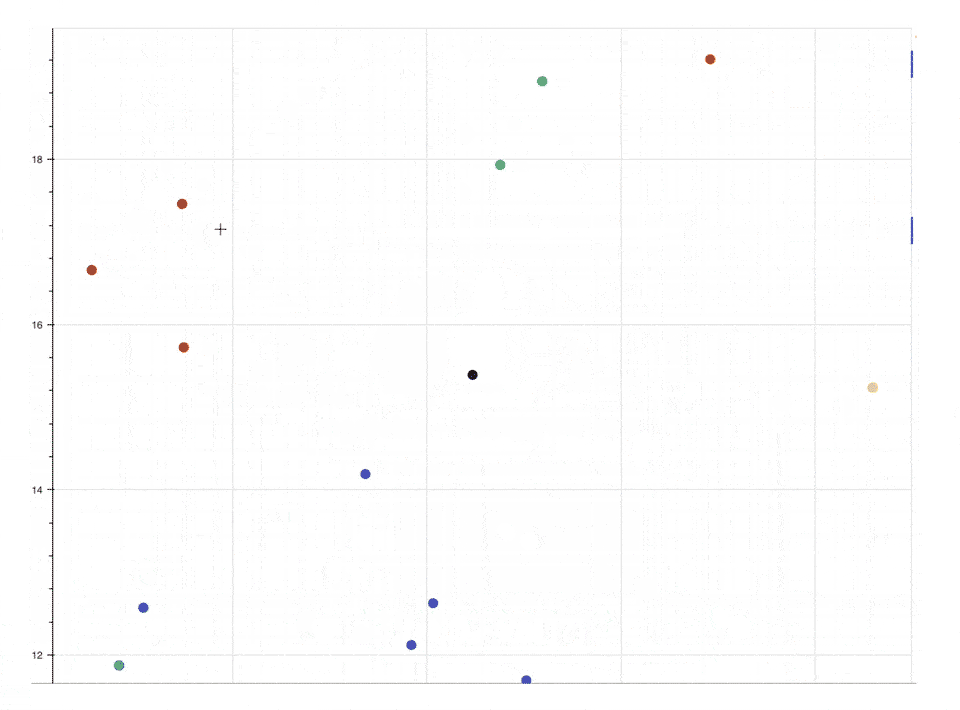
Here is a scatter plot that shows how the classes are well separated into clusters.
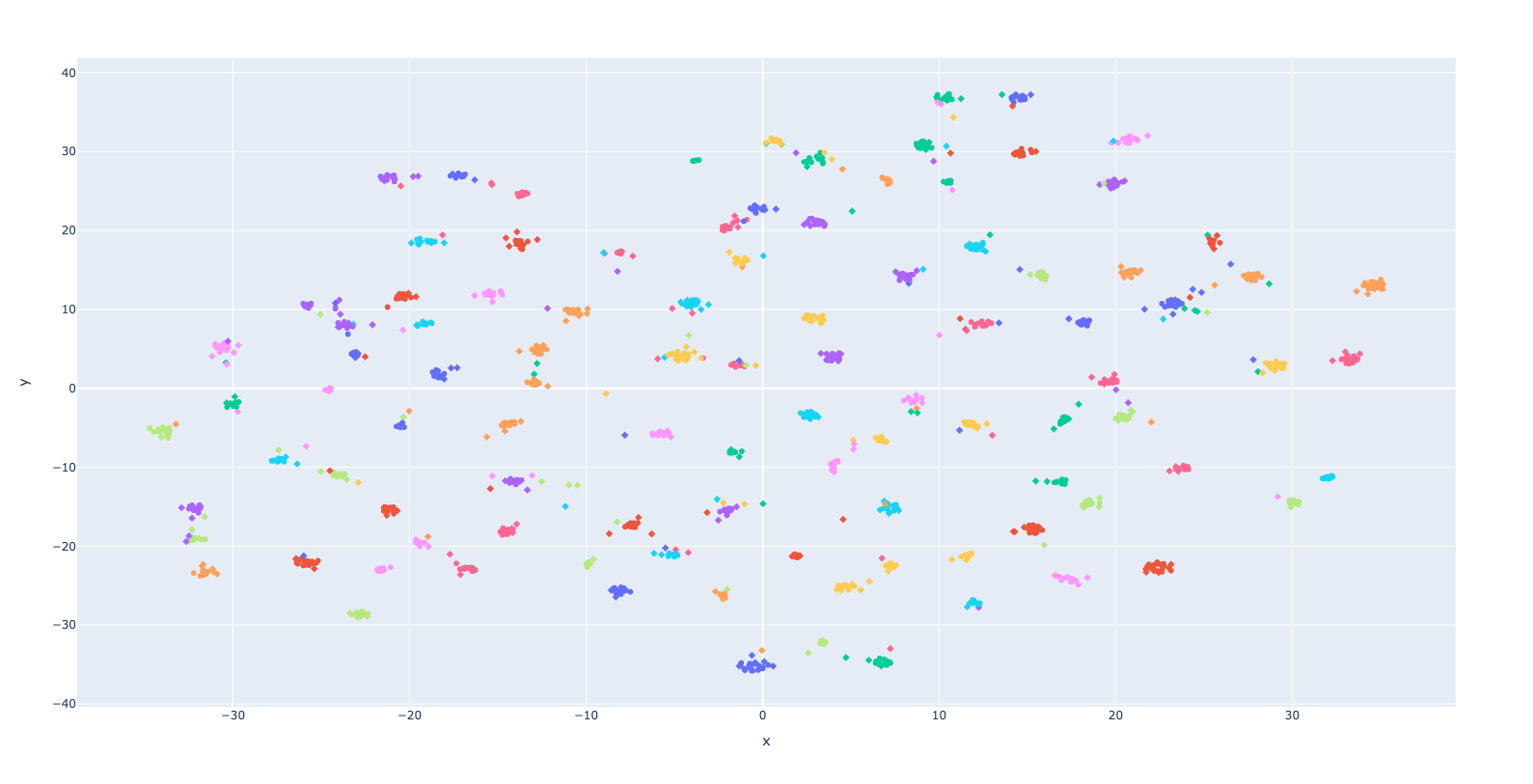
Each point is the 2D representation of the embedding vector computed for a certain video. Points of the same color represent different videos of people making the same sign. A circle means that the video was included in the train set while a rhombus marks validation examples.

When we zoom in on the scatter plot, we can see that different signs which involve more or less similar body movements will be close to each other in the embeddings’ latent space:
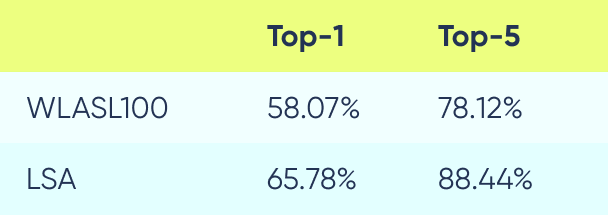
Model classification accuracy
While the model was not trained with classification specifically in mind, it can still be used for that purpose. Here we show top-1 and top-5 classifications which are calculated by taking the 1 (or 5) nearest vector of different classes, to the target vector.
To estimate the accuracy for LSA, we take a “train” set as given and then classify the holdout set based on the closest vectors from the “train” set. This is done using the model trained on WLASL100 dataset only, to show how our model has zero-shot capabilities.
Use Cases and Potential Applications of our Zero-Shot Sign Language Model
The zero-shot sign language model developed by our team can have multiple use cases and applications, including sign language practice, sign language database search, sign classification, and more. A database of signs is required for each of these use cases, though the database size can vary.
It is important to note that while the code is licensed under the permissive Apache 2.0 license, both WLASL dataset and the model itself are shared under the Attribution-NonCommercial 4.0 International (CC BY-NC 4.0) license.
Sign Language Practice
Users can practice sign language skills in front of a camera and have their performance compared to other known instances of the same sign class. Different vector distance metrics can be used to determine how similar the user's repetition embedding is to a vector in the database. This feature can be useful for sign language courses.
Search Sign Language Databases
Users can search a sign language database for signs similar to the one they performed. This could help find similar signs with subtle differences that might lead to misinterpretations. It could also be useful for finding a sign the user saw somewhere but didn’t know its meaning.
Sign Classification
Although not the model's main focus, sign classification can still be performed by choosing the closest sign class in the vector space (top1) or by picking the five closest sign classes (top5) when the use case allows it.
Other use cases
Embedding vectors are very powerful and can be used for many use cases. We are sure there are other use cases for which a zero-shot embedding model can be useful. We encourage you to leave ideas or contributions you might have for this model in our spoter-embeddings repo.
Future Work
Future improvements to this model may include additional work.
On the one hand, further analyzing the training dataset for class imbalances, outliers, etc. makes sense if we set to do some additional data preprocessing eventually.
On the other hand, we could train the model on a bigger subset of WLASL (which contains 2000 classes but we only used 100). This could improve the zero-shot performance on other datasets considerably.
Conclusion
In this blog post, we demonstrated how the SPOTER model can be modified to handle a broader range of use cases, including Sign Language related tasks where there is no available dataset for training. By expanding the capabilities of the SPOTER model, we hope to inspire further research in this area and enable the creation of new end-user applications.
If you found our work interesting, we encourage you to read our other blog post about the product analysis we conducted to apply this technology to the Uruguayan Sign Language. We believe that our research has the potential to make a significant impact in the field of Sign Language recognition and enable more inclusive and accessible technology.
Finally, don't hesitate to contact us if you need help with any machine learning project. Our team is passionate about applying cutting-edge ML techniques to solve real-world problems, and we would be happy to assist you with your project. Thank you for reading!

