

Introduction
In our last blog post, we talked about running Large Language Models (LLMs) locally on your phone to power a privacy-first health assistant. The idea was simple: let your wearable data stay on your device and still get smart, personalized answers about your health, no cloud required. It mostly worked… but it was not perfect. The biggest issues were that the assistant couldn’t really understand trends or tell when your data was collected, which made certain questions hard to answer.
In this post, we’re back with a new idea to fix those problems. We’ll walk you through how we built a smarter, more capable prototype: a local AI agent that doesn’t just respond, but actually thinks (a little) before answering.

Outlining The Solution: Why An Agent?
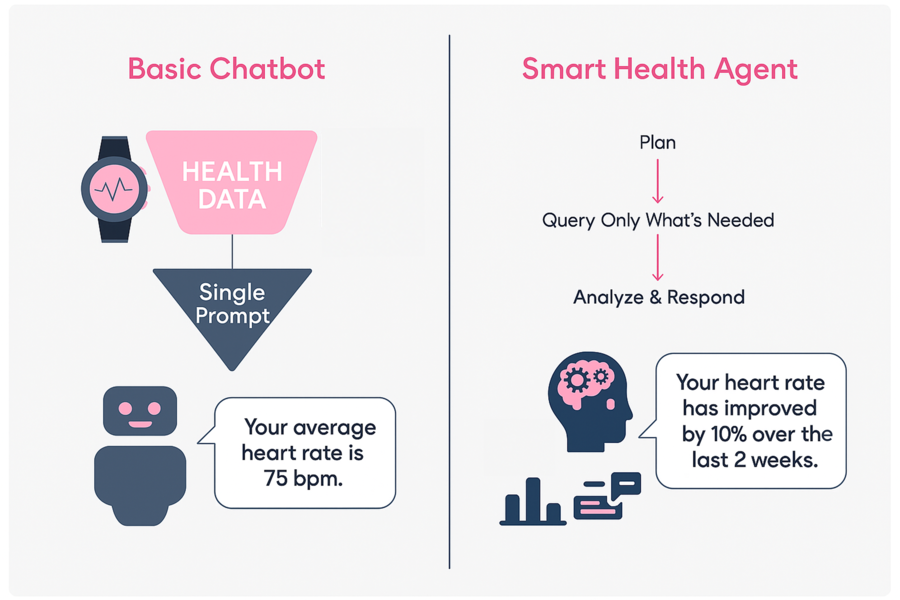
For the solution we were envisioning, a chatbot just wasn’t enough. There was no way to compress all the user’s health data into a simple prompt, and that made it impossible to ask about a specific date, predict trends, or make very context-specific queries without losing precision.
Google Cloud defines AI Agents as “software systems that use AI to pursue goals and complete tasks on behalf of users. They show reasoning, planning, and memory and have a level of autonomy to make decisions, learn, and adapt”.
That’s exactly what we needed. A system that, instead of getting all the data upfront, was smart enough to fetch only what it needed to answer a question. For example, if a user asked: “Has my oxygen saturation improved in the last few weeks?”, the old approach wouldn’t give a clear answer. That’s because it relied on the mean and standard deviation, which doesn’t show whether a metric is going up or down.
An agentic model, on the other hand, could look at just the right slice of data, figure out the trend, and give a clear, useful answer. It’s a big step forward: shifting from a basic chatbot to something more like a smart assistant that understands what it’s doing. This kind of intelligence is what makes the future of local health apps really exciting.
Models & Tool Calling
Previously, we used two local LLMs that received relatively high scores in the AMEGA benchmark: Phi 3.5 and Aloe. Both models fulfilled the purpose of powering a health chatbot that could answer health-related queries using basic context. However, if we want to step up and build an agent, there’s a feature that we need that not all models provide: Tool Calling.
Tool Calling
Tool calling refers to the ability of AI models to interact with external tools. For example, if you asked ChatGPT to plot some data, it could call a charting tool or a Python script to generate the graph for you. In our use case, this ability was crucial, because the model needs to query HealthKit or Health Connect for specific pieces of data, and also request the right statistical operation to apply. Without tool calling, the model would be limited to whatever information was passed in the prompt, making it far less flexible and useful.
For our prototype, we wanted to equip the model with access to basic statistical operations like mean, standard deviation, and linear regression. This would theoretically allow it to go beyond just reading raw numbers and make a much more interesting analysis.
For example, when a user asks, “Is my heart rate improving?”, the model could call a tool to fetch the relevant data from the past few weeks and then calculate whether the trend is decreasing. This kind of analysis simply wouldn’t be possible with a static prompt.
Models That Suit Our Needs
Unfortunately, Phi 3.5 mini, the lightweight, performant model with a surprisingly good AMEGA score does not support Tool Calling. However, Microsoft has released a new model in the Phi family: Phi 4 mini, which does support Tool Calling.
Aloe, the other model that scored very well, also supports Tool Calling. That’s why, for this proof of concept, we’ve chosen to work with Aloe and Phi 4 Mini: two models that combine strong medical reasoning with the ability to interact with external tools.
XLCare v2: From Assistant to Agent
We started experimenting with agentic capabilities: giving the model tools, memory, and the ability to decide what it needed. But getting that to work on-device, with small models, was far from straightforward. Mind you, this section gets a bit into the weeds on the technical side. If that’s not your thing, feel free to jump ahead to the next part.
Different Iterations We Went Through
Our strategy changed a lot during the earliest stages of this new agentic version, because what works with big models (such as ChatGPT) does not always works with these much smaller ones.
No. 1: Simple approach
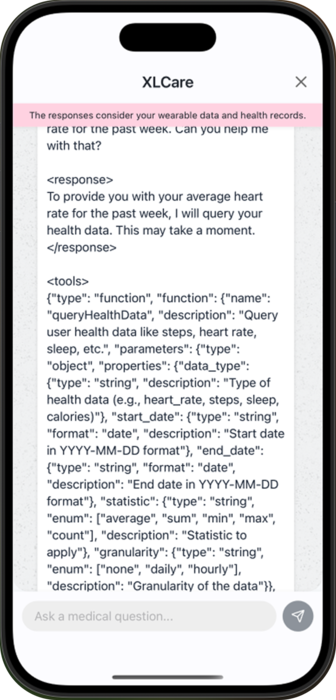
At first, we thought that a simple approach would work best. Simple prompt, letting the model know what tools it could use.
This is an example of the type of prompts that we used at this stage:
'You are a helpful assistant that interprets user health-related questions and returns structured queries for health data retrieval.' +
'Your job is to translate user requests into well-formed JSON objects that can be used to call external health services such as Apple HealthKit.'However, we could not get a conversational response using this technique.
No. 2: Triple prompt
Since it wasn't responding in the conversational way that we intended, we tried a different strategy: breaking down the message in three parts. That way, we could customize each part of the prompt specifically. This is the structure we thought of:

For that purpose, we designed three separate prompts that would be used in each part of the message. That way, the context could be much smaller and leave less room for mistakes or confusion. Also, we provided the model with a simple grammar—a set of rules and examples—to guide it in formatting its responses as JSON.
This were the first three prompts that we tested:
const initialPrompt = {
role: 'system',
content:
'You are a health agent. Greet the user warmly and supportively when they ask about their health. Inform the user that you are going to check some metrics to provide a better response for their query.',
};
const toolPrompt = {
role: 'system',
content:
'Convert the user health question into a structured health query using queryHealthData.',
};
const answerPrompt = {
role: 'system',
content:
'Answer the users health question based on the tool result. Be helpful and concise.',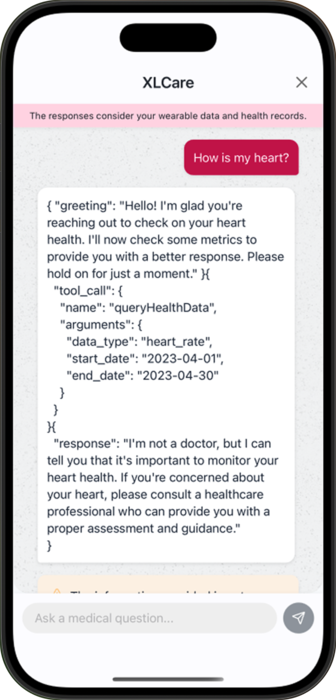
At this point we were still dealing with some formatting issues such as all the output being in JSON format due to the grammar provided. And of course, we forgot we needed to call the tool and actually pass the results as context for the model to be able to arrive at a conclusion. But this was definitely a step in the right direction!
No. 3: Prompt Evolution
We continued iterating over the three prompt approach, in search for better results. Our prompts started looking like this:
Initial
'You are a supportive health assistant. When a user asks a question about their health, choose one of the following two actions:\n\n' +
"1. If the question clearly requires personal health metrics that you don't have (e.g. heart rate, sleep, steps), greet the user warmly, inform them that you'll check that information, and include <tool> at the end of your message to request the data. Do not ask the user to provide data manually." +
'2. If the question can be answered generally without personal data, respond directly and concisely. In this case, instead of <tool>, use <end> at the end of your message.\n\n' +
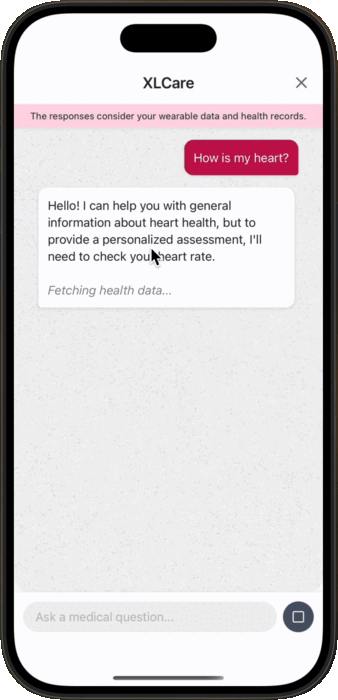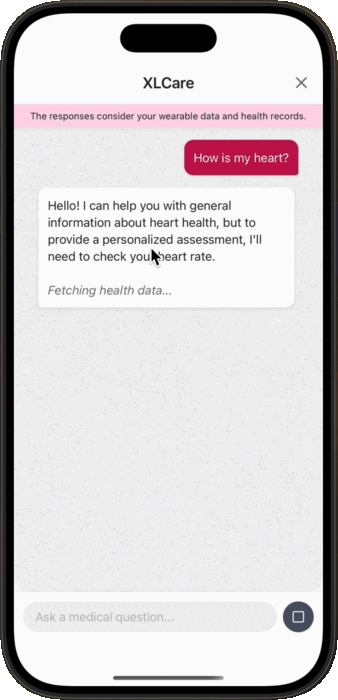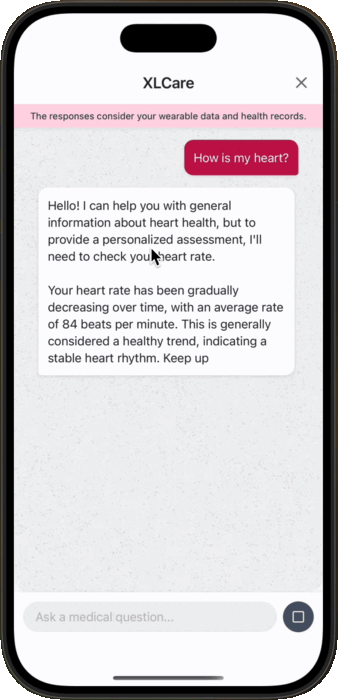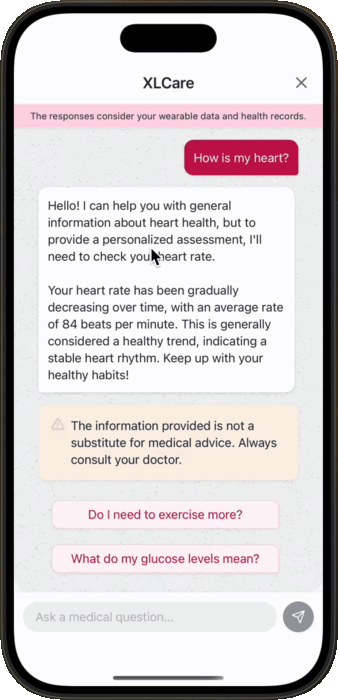
'You must pick only one path. Never include both <tool> and any direct health advice in the same response.'In this version of the initial prompt, we added simple logic to help the model decide whether to call a tool or just respond directly. If no tool was needed, the message would end there; otherwise, it would continue with the appropriate tool call.
At this point, we decided that for XLCare to behave like a true agent, it should be able to decide whether to continue calling tools or respond directly, based on whether it has gathered enough information to answer the user’s question. For that reason, it was necessary to combine steps two and three in a single prompt.
Tool + Final response
export const toolPrompt = {
role: 'system',
content:
'You are a supportive health assistant.\n\n' +
'Follow the plan. For each unique data request (e.g. different date ranges), make one tool call. Never skip steps or repeat calls with the same parameters.\n\n' +
'**Tools:**\n' +
'- `queryHealthData`: needs `data_type`, `start_date`, `end_date`, `statistic`\n' +
'- `createHealthChart`: needs `data_type`, `start_date`, `end_date`, `aggregation`\n\n' +
'**Checklist:**\n' +
'- [ ] Covered all date ranges?\n' +
'- [ ] No duplicate calls?\n' +
'- [ ] All data gathered?\n\n' +
'Only answer the user once all tool calls are done.\n' +
'Explain results clearly, without jargon. Be concise, relate findings to norms, and ask a follow-up (e.g. "Want to see a chart?").',
};For the tool prompt, we decided to include the current date—since the model seemed to think it was still 2023—and a clear explanation of the statistics it could request, depending on the user's question.
The model is now able to call as many tools as it needs, within a set threshold, and decide when it has enough information to return a final response.
As a result of combining the prompts, we finally had the first working agent version of XLCare!
No. 4: Health Charts
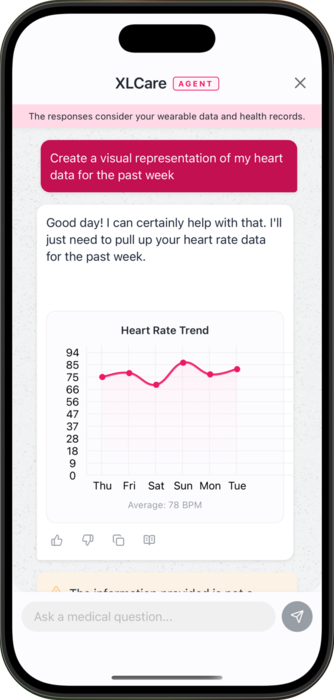
We really wanted to test the limits, so we decided to give the model another tool to play with. We added another function to let the model create a chart of the user’s health data if requested. We had to modify the tool prompt to induce the model to use the chart tool whenever the user asks for a visual representation.
`Convert the user's health question into a structured call using the correct tool: queryHealthData or createHealthChart. Today is ${new Date().toISOString()}.\n\n` +
'Follow these rules:\n\n' +
'**For queryHealthData:**\n' +
'- Always request data from the **past 2–3 weeks**.\n' +
'- Choose a single `statistic` based on the question:\n' +
' - "how is my [metric]" → `mean`\n' +
' - "does it vary" / "is it consistent" → `stdDev`\n' +
' - "has it improved"/"changed"/"trended" → `linearTrend`\n\n' +
'**For createHealthChart:**\n' +
'- Choose aggregation:\n' +
' - Past 1–2 weeks → `daily`\n' +
' - Past 3+ weeks → `weekly`\n' +
'- Always include `start_date` and `end_date`.\n\n' +
'Only generate one tool call per request.'Then, using react-native-gifted-chart, we were able to create the chart that the LLM requested.
No. 5: Planning
There was still a use case where the model’s response was sub-optimal: when users asked it to compare statistics. In these cases, it would sometimes mix up dates, forget one of the periods, or redundantly request the same data multiple times.
To fix this, we added an intermediate planning step. After the initial user prompt, the model is given the question and asked to generate a structured plan for how to fulfill the request before any tools are called.
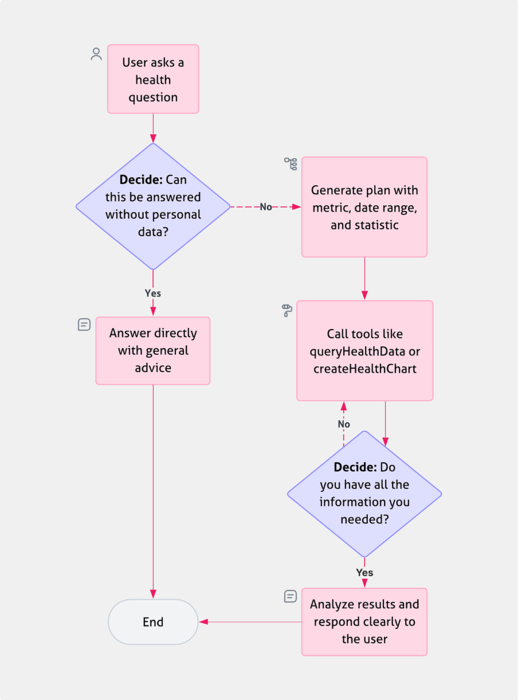
The planning prompt looks like this:
export const planPrompt = {
role: 'system',
content:
'Create a one-line plan starting with `Plan:` that captures everything needed to answer the user’s question.\n\n' +
'Include:\n' +
'- The correct `metric`: heart_rate, steps, glucose, or oxygen\n' +
'- Exact `start_date` and `end_date` for each time range\n' +
'- The right `statistic` based on intent:\n' +
' • average/level → `mean`\n' +
' • fluctuation/consistency → `stdDev`\n' +
' • change/trend → `linearTrend`\n' +
' • chart/graph → `createHealthChart`\n\n' +
'Use this exact format:\n' +
'`Plan: 1. get the [STATISTIC] of [METRIC] from [START_DATE] to [END_DATE] ... to [END_GOAL]`\n\n' +
'Ask for weeks or months of data.\n' +
'Only output the plan.',
};Having a plan allows the model to separate the steps and treat each subtask explicitly, reducing ambiguity and preventing issues like redundant tool calls or incomplete comparisons.
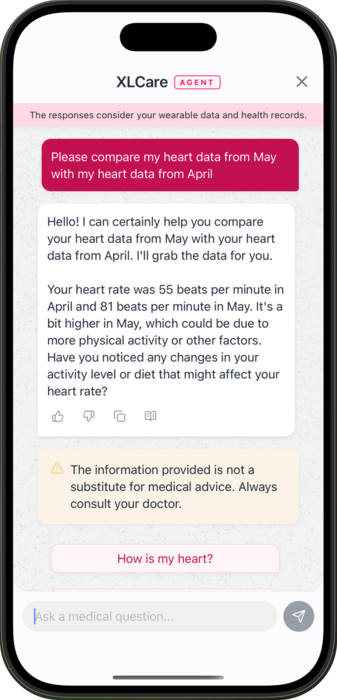
The prototype can be downloaded on the App Store or the Play Store.
Testing
Even though we can evaluate the models' medical accuracy using the AMEGA benchmark, we still need to test our agent to make sure it's correctly interpreting instructions and using the appropriate tools.
We created our own set of 60 questions to evaluate the agent’s ability to use the correct tools in different scenarios. It’s important to note that this test doesn’t measure medical accuracy, it only checks whether the agent calls the right tools based on the prompt.
Here are a few examples of the types of questions we used:
- “What is my average heart rate over the past week?” — the agent should call a tool to get a statistic.
- “Show me a visual representation of my steps from last month.” — the agent should call a tool to generate a chart.
- “Is walking better than running for heart health?” — no tool needed; the agent should just respond in natural language.
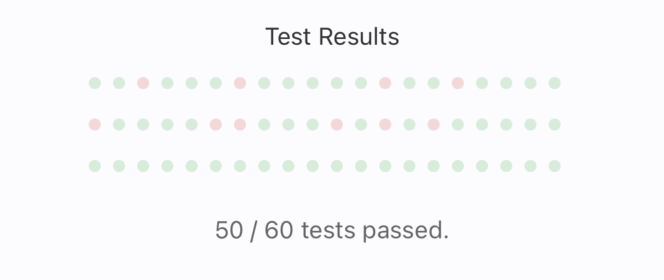
The test results showed that the agent made the correct tool call in 50 out of the 60 scenarios, giving it a success rate of about 83%. While there's still room for improvement, especially in edge cases or more ambiguous prompts, this is a strong starting point for an on-device health agent.
Conclusions
So, is it possible to create a fully local AI agent? We’ve discovered that the answer is yes. Is it practical for the average user? Not quite.
Surprising no one, the fully on-device agent approach comes with limitations. It shares all the tradeoffs we discussed in the last blog: system requirements, long download times, and the large storage space models need. It also adds a few new ones: small models handle simple tasks quite well, but things get tricky when they're faced with too many instructions or options, like choosing between multiple tools.
But if privacy concerns outweigh the less-than-ideal user experience, going fully local is definitely an option worth exploring.
What’s more, small models are improving almost daily: getting smaller, faster, and more capable. Start building a local agent now, and in a month, the tech might already be better suited for it. Then again, no one really knows where things will land. But that is part of the fun.