


Recommendation engines can rapidly increase online business revenue and boost customer loyalty, both crucial for sustainable growth. In this blog post, we��’ll go through the main challenges, and pros and cons we faced implementing and deploying such solutions for a big apparel brand, the different approaches to implement recommendation engines, and best practices.
First things first... what exactly is a product recommendation engine? And how can I take advantage and put it to work so it drives those sales? Keep reading to find out.
What's a product recommendation engine?
You probably have Twitter, Netflix, or buy browse through Amazon. All these three platforms use recommendation engines intensively throughout every end-user application touchpoint. Twitter suggests who you should follow, content you might like, top trendings topics, etc.; Netflix recommends movies and series categorized by genre, top watched, Amazon shows related, and “Frequently bought together” items, and so on.
A product recommendation engine is the software component that analyzes data about a platform's end-users to infer what type of products they may be interested in. It considers the user's behavior, activity, preferences, feedback, and products features to generate personalized recommendations.
Modern Recommendation engines use AI and Deep Learning to infer personalized and contextual recommendations and constantly evaluate and improve their model results.
Why your platform needs a recommendation engine?
Many businesses quickly understood the value and importance of solid recommendation systems. The number of clients coming to our Machine Learning team looking for one has made this shift clear. No matter your industry, in a time when online presence is everything, recommendation systems might be a game-changer for your business's platforms.
The main reason to adopt a recommendation engine is simple: increasing your revenue.. However, there are other reasons such as:
- Customer Loyalty: Recommendation systems enable a high level of personalization, which the user perceives as high value.
- Platform engagement: Customers quickly discover new items to watch, interact and buy, making users spend more time on the platform and consume more.

Is it worth investing in a recommendation system for my business? How much time or money will it take? Will I be able to see results quickly? Our experts can answer these and many other questions for you. Schedule a free consultation call to learn more opportunities you might be missing.
How does a product recommendation engine work?
In a nutshell, modern recommendation engines collect customer data (previous purchases, checkout cart, favorites, viewed items, etc.) to generate personalized recommendations based on business guidelines and objectives. Developing recommendation systems can be very complex under the hood. Collecting user data to know personal taste is just the beginning. Afterward, the data is processed, transformed, and structured so that deep learning algorithms can generate those items that better fit the preferences. Finally, the recommendation is shown to the user at the right moment.
This workflow never stops. The system has to constantly gather new user data to be updated on shifting interests, transform this data, and update the suggested items on an hourly, daily, weekly, or monthly basis (depending on the product need, user activity, and product catalog changes).
Let's dive into each step...
Step 1. Collecting Data
Enables the system to understand end users' tastes and preferences. There are two types of data the user provides.
Activity data provided implicitly:
- Opening a promotional email.
- Searching by a specific term.
- Viewing certain products.
- Being in a particular location/season.
Data provided explicitly by app users:
- Reviewing a product.
- Adding products to wish lists / favorites / Watch later / etc.
- Navigating among categories, applying content filters.
- Adding or removing items from the shopping cart.
The data collected will be different depending on the business domain. For example, shopping cart information doesn't make sense for a streaming platform.
Each platform and business is unique, so gathered data should be analyzed carefully to produce accurate predictions according to recommendation engine goals and metrics.
Luckily, there are several SaaS solutions out there to seamlessly gather end-user activity and preferences, such as Segment, Firebase or Google Enhanced Ecommerce. These tools don't require much effort to integrate since tracked events and data can be configured rather than coded.
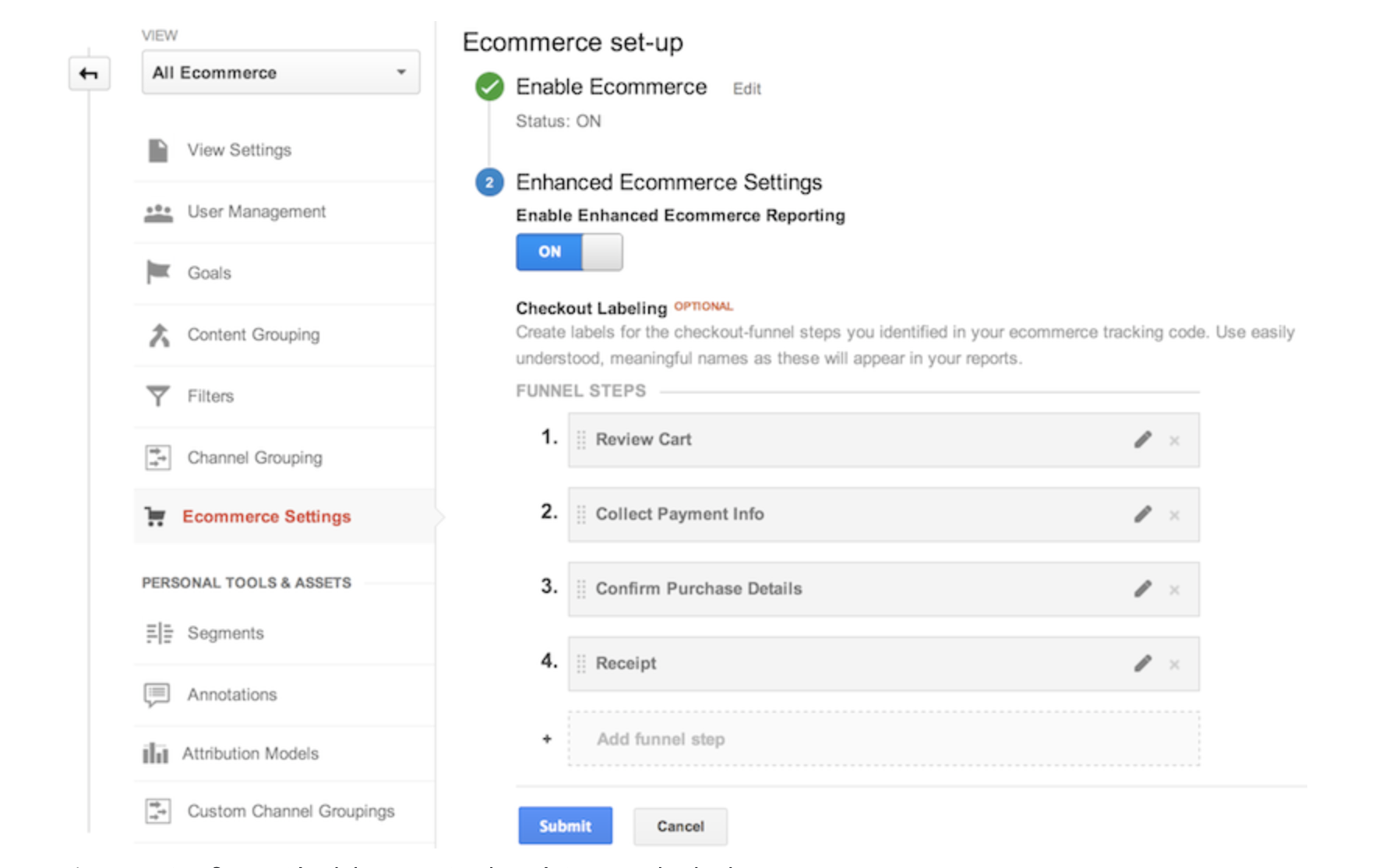
Step 2. Making Data Available
The vast amount of data collected needs to be accessible and consumed by ML models. There are experts dedicated to managing data at scale. Data Engineers build ETL systems that collect, manage, and transform raw data into useful information. Recommendation engines need to perform these processes constantly, so data is updated and can deliver accurate recommendations.
Airflow is a popular ETL solution that allows to transform and structure data using data pipelines, but there are many others approaches to manage the data.
Step 3. Build the engine
There are several approaches; let's go through the top three, from the simple to the powerful and complex.
A. Content-based filtering.
The Content-filtering approach uses information about people and things as connective tissue for recommendations. It labels each person and item with some known attributes.
For instance, if we're a streaming service, we could tag each movie by genre (drama, terror, action, comedy, etc.). Then each user has a numerical score indicating how much they like a genre. Finally, we connect and cross this information to recommend movies.
Basically, this approach uses item features to suggest other items with similar characteristics as shown in the image below.
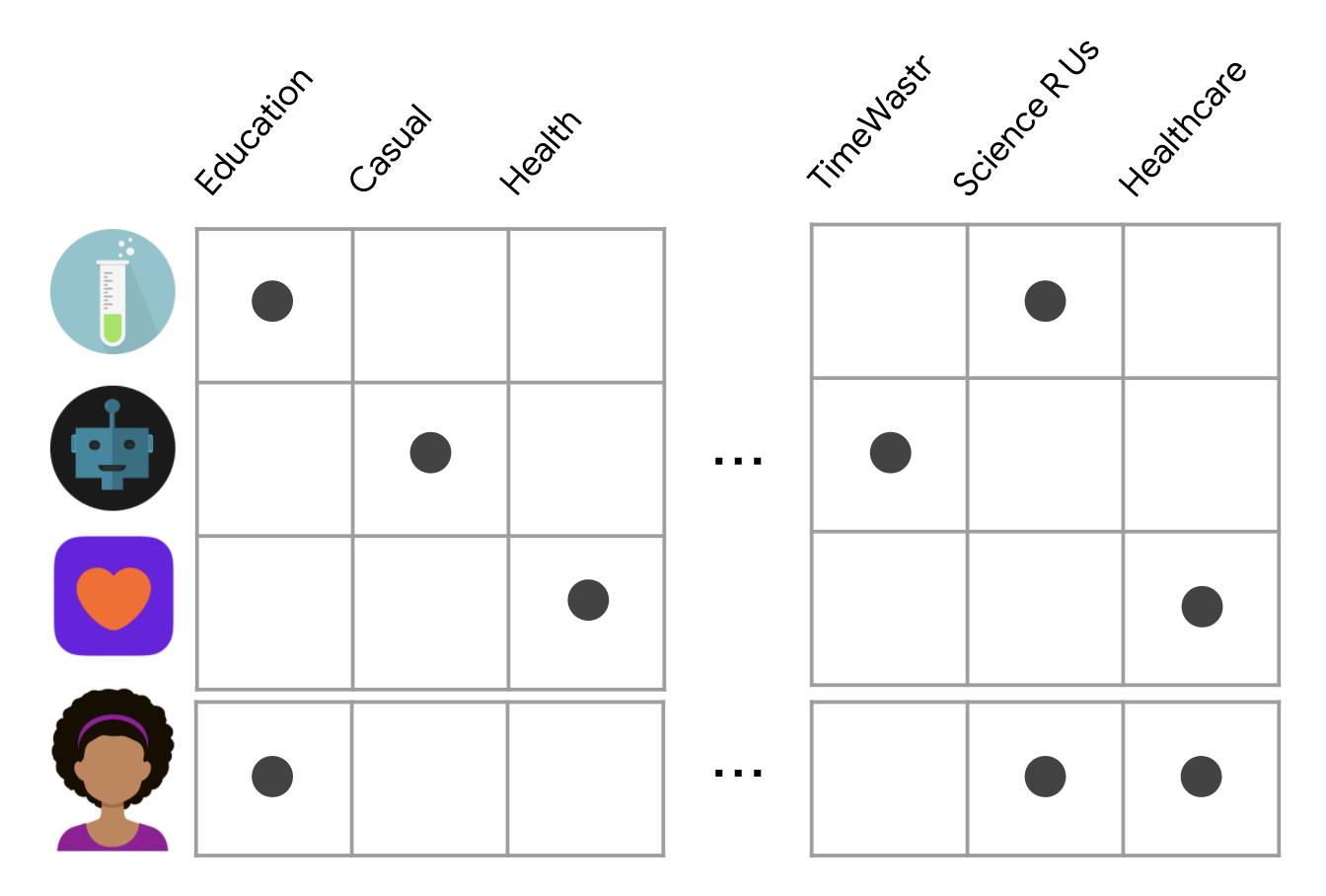
In the illustration above, each row represents an app, and each column represents a feature (the app category). Knowing which apps were installed by the user and their categories allows the algorithm to provide recommendations.
Its biggest limitation is not using user similarities; this approach only feeds on the item's characteristics. Additionally, features are not automatically inferred, so a domain expert is needed to create and set them up.
Another restriction is the scope of the recommendation because it's based on past interests which are the only ones it has.
An advantage is it doesn't require complex data from other users; only data about the user we want to generate the recommendations to is needed (besides the item's features :)). This allows the solution to scale up easier when working with a considerable amount of users.
B. Collaborative filtering
The idea behind collaborative filtering is simple; you would probably like the same things as people with similar tastes. So collaborative filtering doesn't just use item features like content-based filtering; to generate recommendations it also considers similar users and what they like.
It tries to infer users' features based on the preferences of other similar users. It's important to notice that the features are not domain-based and could not be interpreted by a person in this case. It's a machine-learning algorithm that generates them using underlying patterns in the data.
Which one is better? Collaborative filtering predicts the recommendation in the same way but is more accurate in discovering those features human beings can't. Not to mention its ability to update and adapt recommendations over time.
Notice these previous approaches can be combined, creating well-known hybrid recommendation systems in the industry.
C. Deep Learning Model Solutions
Recommendation systems that use deep-learning models normally outperform the approaches presented above. First, because they're customizable and flexible, we provide user interactions and user non-interactions as examples to train the model, and it infers items with more probability of being interacted with.
The model's input data might be a mix of domain-based data and deep learning, but typically the model by itself does everything or at least is capable of doing so.
It's essential to have a recurrent cycle of testing and evaluating with real users, retraining, and deploying the model. Typically, you will apply DevOps best practices to your ML workflow, which is known as MLOps. This means automating these tasks and ensuring the model stays up-to-date with the latest data and its performance does not degrade over time.
Unfortunately, the benefit of flexibility comes with a downside; it's more complex to design, train and deploy.
Input data should be carefully analyzed since it impacts the accuracy significantly; it's essential to have a strong knowledge of the domain to properly design the model, and select the correct input data to achieve the results.
There are no hard-coded rules in the most typical design; the deep learning model learns from the data; we just have to provide precise training data. However, to achieve better results, teams will mix hard-coded data with this approach.
TensorFlow recommenders is a pretty popular ML framework in the industry that's worth checking out.
Challenges of building a Recommendation Engine (and how to address them)
Choosing the right strategy
The north star of a recommendation engine is clear; it ultimately must drive revenue. The tricky question is how to successfully prepare the data, design, train, evaluate, and deploy the model.
A consultancy company like Xmartlabs will help you navigate these challenges, understand the platform needs and create a feasible project plan.
- Discovery stage: We get into your company's needs and goals, and help your team discover new opportunities by leveraging AI-powered solutions. We also agree on the metrics to measure its performance.
- Evaluating available data: As we explained before, gathering data and tracking users’ activity is vital. Depending on the desired outcomes and goals, we uncover data requirements.
- Defining what data is required to provide recommendations.
- Ensuring the data is well structured and provided on time.
- Ensuring data storage, workflow, and update rate are suitable according to project goals.
- UI improvements: Enumerating screens that will show recommendations to the user. Evaluate UI elements that need change and their impact. Create low fidelity and then high-fidelity design for each screen.
- Agree on a potential solution: Our specialists design a possible solution, propose a technology stack and services to build, train, deploy and monitor the recommendation system.
- Feasible roadmap to go-to-market fast: Considering everything below, we create a feasible roadmap and assign a dedicated team to work in each solution layer (Product, Data, ML model, UX).
People's tastes change over time
People's tastes evolve, so solutions should adapt the RE to provide newer recommendations taking those changes into account. Sometimes the product catalog is constantly updated, but these newly released items have no reviews or ranking. However, all these items need to be discovered as they are new products or fresh content.
Its model should be constantly trained, evaluated, and deployed to improve the RE performance. It's likely some data preparation needs to be done too. MLOps, which are essentially DevOps for machine learning, could handle these tasks and automate most of the process, if not all.
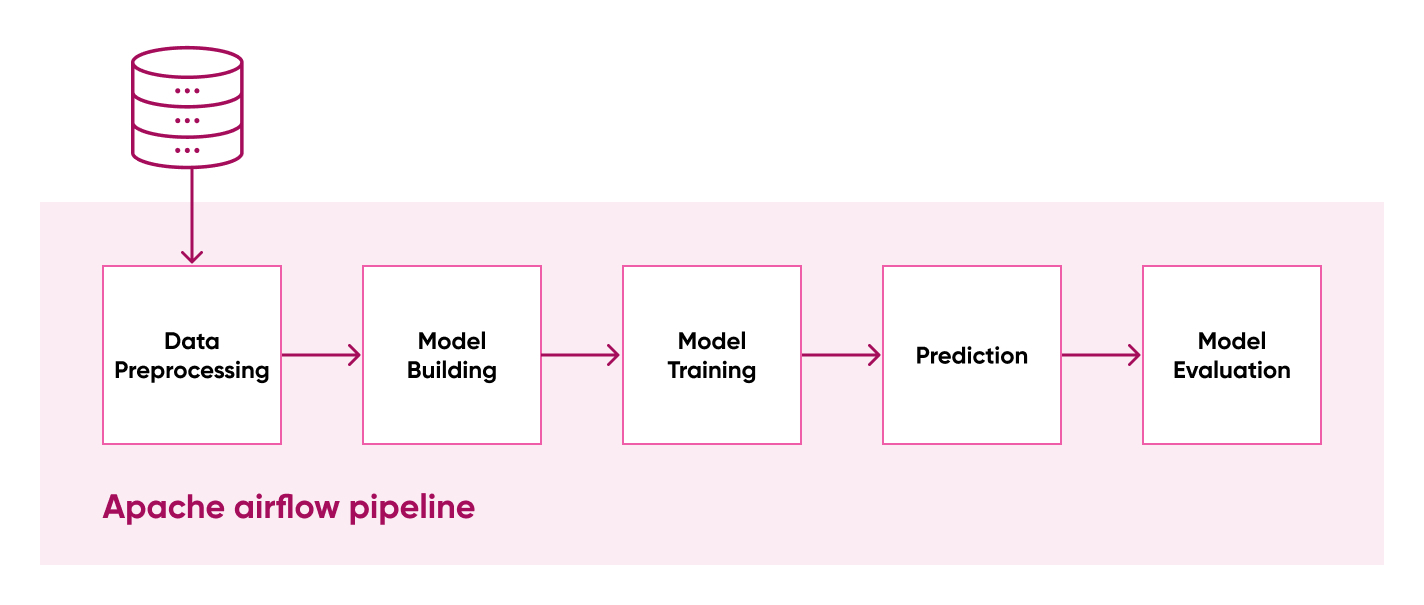
According to the business domains and goals, the engineering team should decide when and how frequently the model needs to be updated. Having strategically chosen the metric to measure model performance is crucial to improve it. Strategically defining what metrics should be used to monitor and measure recommendations, accuracy is vital to redeploy a retrained model. The engineering team should know when changes improve the system and what's the cause.
The product catalog is huge
Certain platforms have a long list of items. eBay and Amazon, for instance, have hundreds of thousands of items to recommend for a particular end-user.
This makes it difficult for the model to determine which items to recommend. A possible solution could be categorizing the items in families of products, reducing the possible items to recommend. The model suggests a product family to then choose an item within the family.
First-time users
Making recommendations for first-time users involves extra complexity. Not having their personal preferences or tracked activity yet, makes show trending items and most purchased items the natural solution. Another possibility is to recommend products that other new users have interacted with first in the past. For instance, an online IoT store could recommend a Raspberry Pi and others edge devices as the system infers new users are primarily looking for them, but for older users, it could recommend gadgets to the Pi the user already has.
Regardless of the approach adopted, the recommendations become more precise and personalized as the user activity is gathered. The more the user interacts with the platform, the better the recommendations the system will provide. It's an incremental and continuous improvement process that makes its recommendations increasingly accurate and personalized.
Not considering business insights
Fashion e-commerce needs to consider the season, or some important dates like Christmas, where the demand for certain items increases. Customer preferences can eventually shift according to external factors anytime.
Deep Learning-based recommendation systems can learn these patterns by themselves, but the engineering team can facilitate these business rules explicitly.
The engineering team can tweak input or output data to generate better results or filter undesired items accordingly.
Not able to measure outcomes
If you can't measure it, you can't improve it. As simple as that! Recommendation systems must be measured with specific metrics to evaluate ROI, its success, and update the engine from time to time.
Evaluating the business value of a recommendation system depends mainly on the company’s business strategy and its business domain.
The most common metrics can be categorized as:
Click-throught rate
When an item is recommended and viewed... Was it clicked? How often? This strongly depends on where the recommended items are displayed, if there are more recommended items around, etc.
User behavior and engagement
For a streaming platform, these metrics should show if the recommendation engine makes the audience spend more time watching series or movies or if there's an increase in the "Save to watch later" list? etc.
Revenue Indicators
Recommendations make users spend more money? Are users adding more items to the cart? Revenue indicators are great to measure overall RE performance.
Adoption and conversion Rates
Click-through rates are okay, but we are also interested to know if these suggested items were purchased, added to the cart, or watched. This indicator reflects whether the recommendation engine is useful to the end-user or not. Otherwise, they can be interested in navigating to the recommendation item but never consume it, which is a waste of time for the user.
Not considering every end-user touchpoint
Evaluating every change and its corresponding benefit the end-user would experience by implementing the RE is crucial. Taking Amazon as an example, several views show recommendations:
Top sellers and most popular items on the homepage - if the user is not logged in
Several screen sections showing “More items to explore” - based on previous purchases, viewed items, etc.

“Frequently bought together” section in the item view

When added a Kindle item to the card
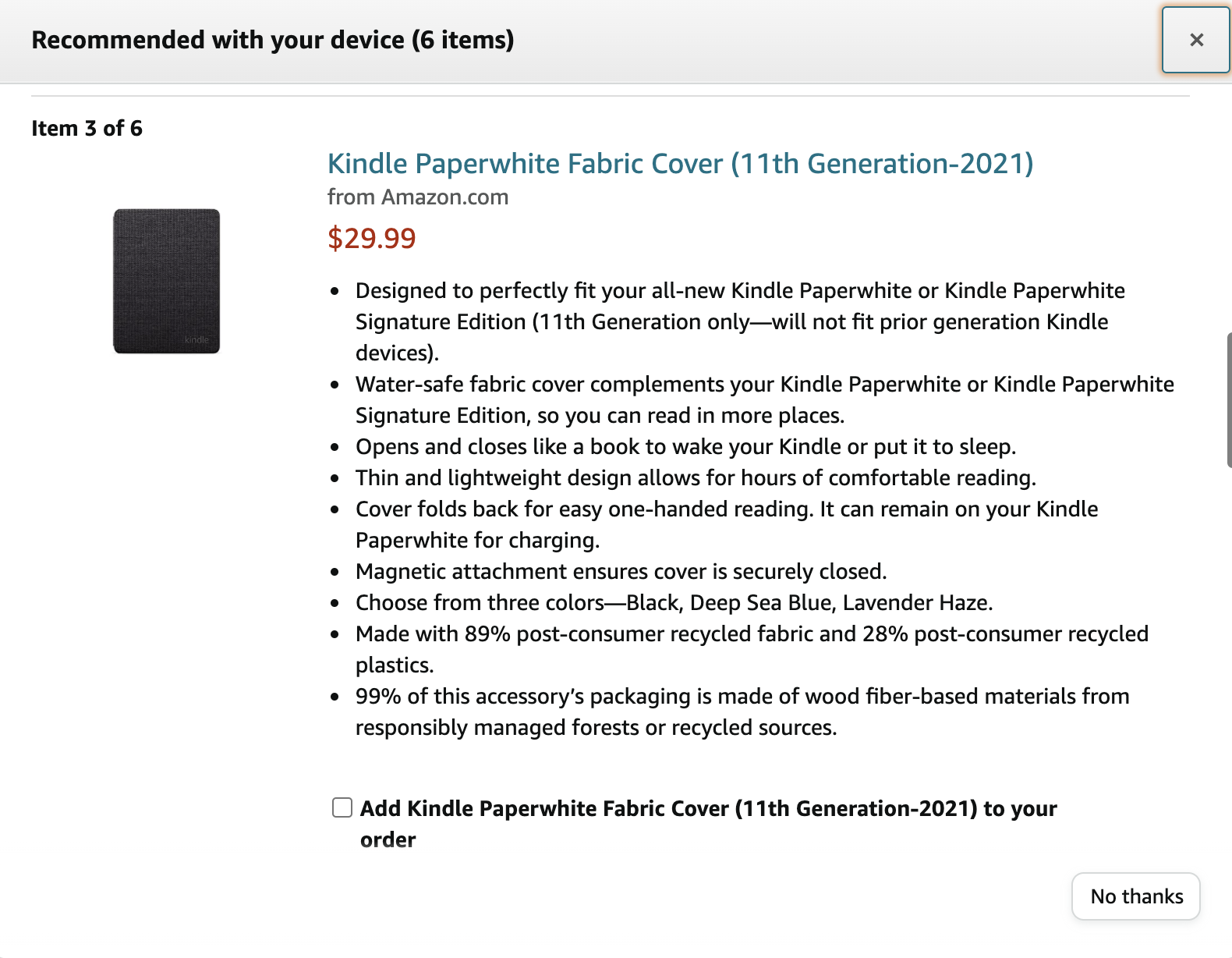
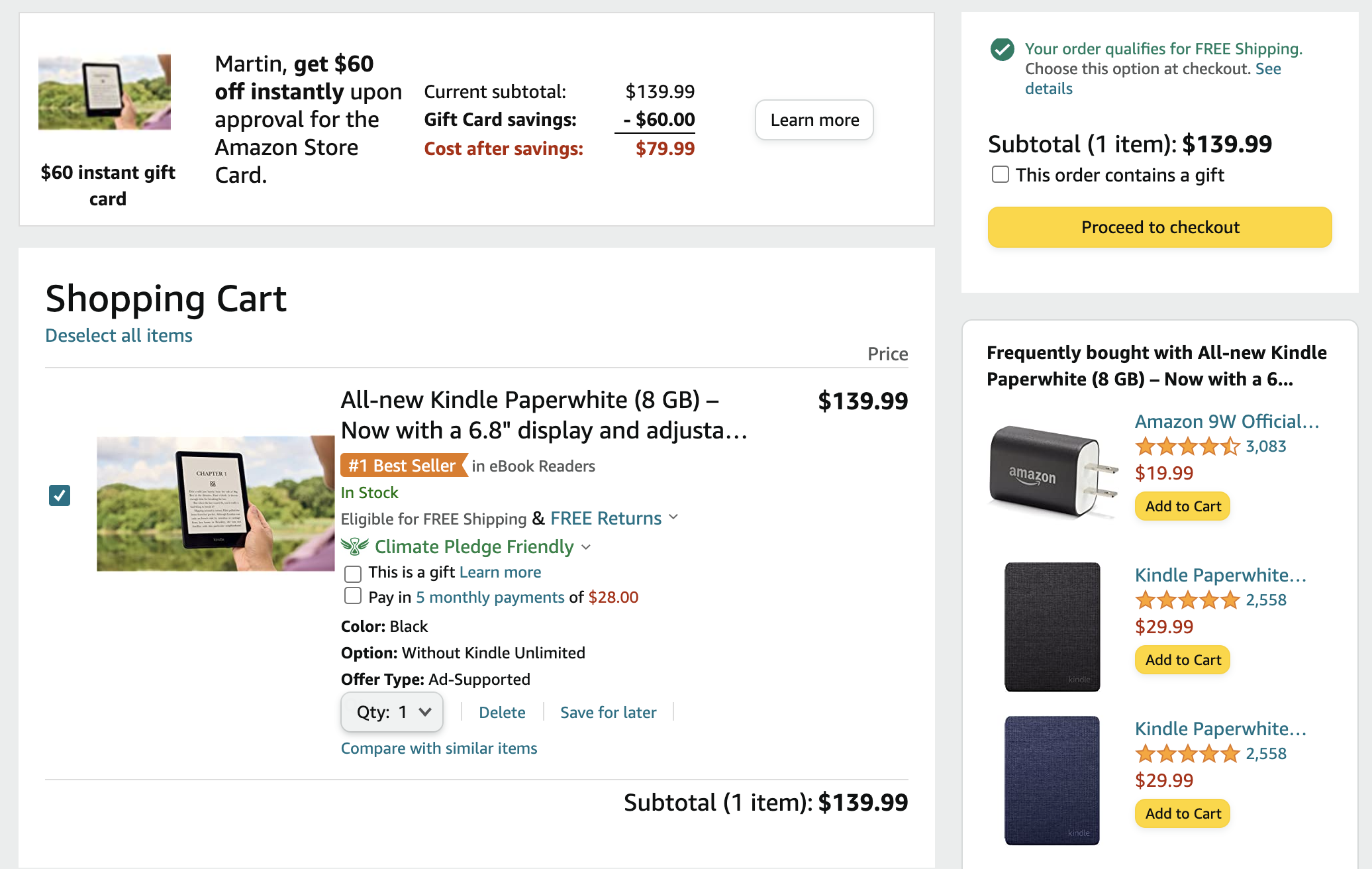
During checkout process
Closing thoughts
If you read this far, you probably have a better understanding of how recommendation systems can boost your business. And you'd probably appreciate the complexity of building one that requires a wide range of specialists collaborating together.
Each product is unique, and the challenges can diverge accordingly. All the challenges we presented were experienced during years of developing these solutions for our clients.
In the upcoming blog posts, we'll be going into details on how to implement them, different tools and approaches to solve each of the steps presented below, as well as code and practical examples.
If you are considering leveraging recommendation engines...Don’t hesitate, get in touch to get a free consultation with our specialists.

