


Building a secure, local RAG system for healthcare data can dramatically improve how organizations leverage their FHIR records. This article builds upon our previous work on Parsing FHIR Data into RAG, where we explored strategies for manipulating FHIR data for LLM systems. While our earlier piece focused on transforming structured healthcare data into LLM-friendly formats, we now explore practical implementation using llama.cpp - emphasizing privacy, data control, and performance optimization.
Why deploy a RAG locally?
Deploying a local RAG system offers distinct advantages, particularly in industries where data privacy, regulatory compliance, and control are non-negotiable. By keeping systems and data in-house, organizations can ensure that sensitive information remains within their infrastructure, mitigating the risks associated with sharing data through external services.
Some industries notable for their stringent data privacy regulations are:
- Healthcare: Patient data, such as medical records, lab results, and diagnostic reports, is subject to regulations like HIPAA in the U.S. A local RAG system ensures that this sensitive information remains within the organization’s control, minimizing risks of breaches or non-compliance.
- Finance: Deploying locally helps organizations prevent the exposure of sensitive financial data to external cloud environments, ensuring compliance with regulations like SOX and avoiding complexities in cross-border data transfers.
- Legal Services: Law firms handling confidential case files, client communications, or intellectual property documents can benefit from local deployments, ensuring that these materials remain secure and are not inadvertently exposed to third-party services.
However, configuring and maintaining a local deployment does require significant technical expertise. Ensuring that the system runs as efficiently as possible—by making the best use of both CPU and GPU resources, for example, or selecting the right quantization level for models.

While cloud-based solutions offer superior scalability and infrastructure management, local setups remain a compelling choice for prioritizing data control, security, and compliance. That said, if your use case doesn’t strongly require a local deployment, there may be better alternatives offering easier scalability and maintenance.
Why Choose llama.cpp?
llama.cpp provides an efficient way to run LLMs locally, offering ease of configuration and control over crucial parameters like context size, prediction tokens, and CPU/GPU cores. Its C/C++ base and lack of external dependencies simplify integration, making it adaptable to various hardware setups.
Key optimizations include:
- Apple Silicon: Leverages ARM NEON, Accelerate, and Metal frameworks for improved performance.
- x86 Architectures: Optimized with AVX, AVX2, and AVX512 for better performance on modern CPUs.
- Quantization: Supports from 1.5-bit to 8-bit quantization, reducing memory consumption and speeding up inference.
- Hybrid Inference: Allows combined use of CPU+GPU, optimizing resource use when VRAM is limited.
- Docker Integration: Facilitates deployment, enabling easy access to performance metrics like prediction time and token generation rate.
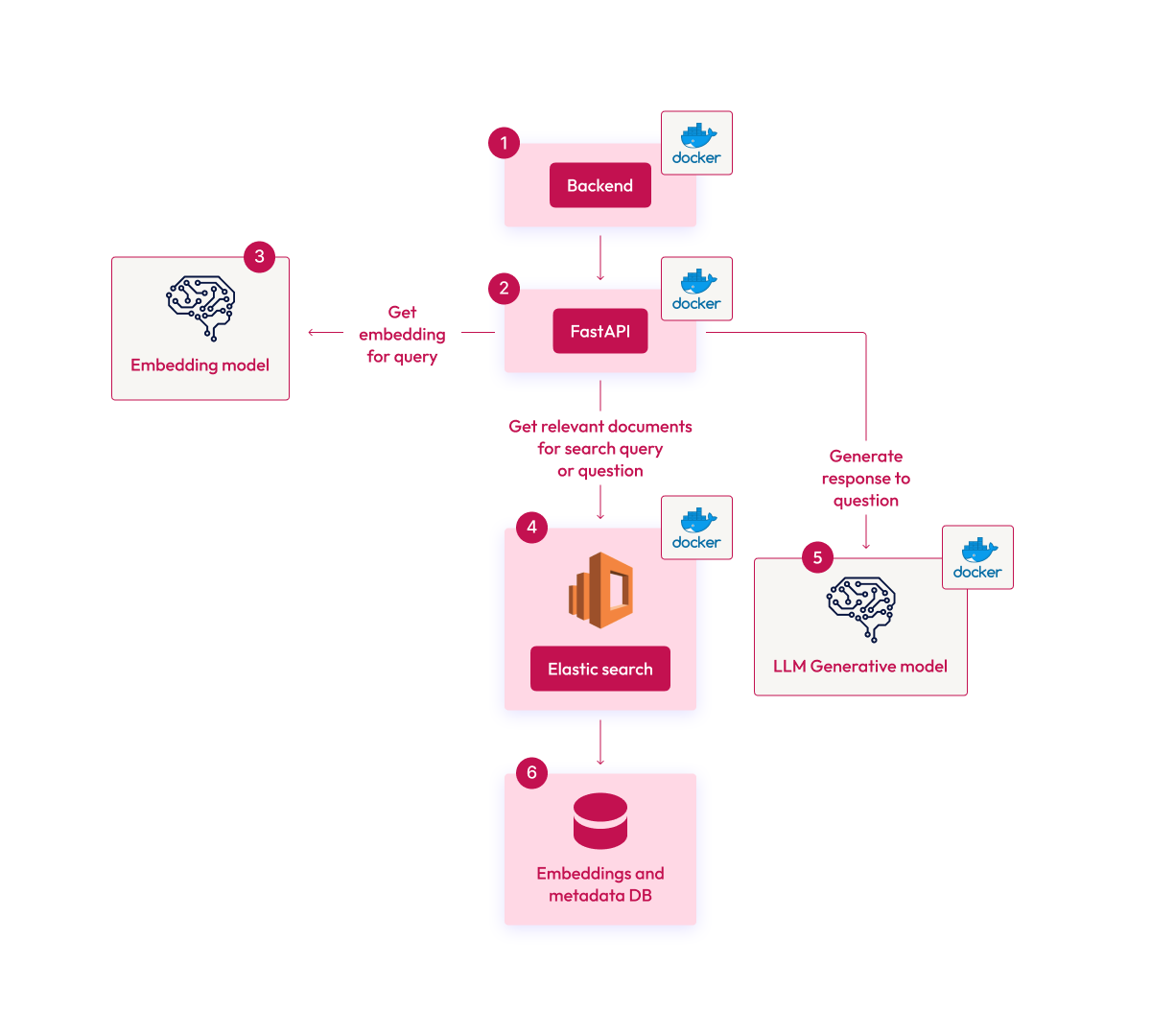
Architecture
The local RAG setup comprises three main components:
- FastAPI Container: Manages user requests, extracts embeddings, and performs searches in Elasticsearch.
- Elasticsearch Container: Stores embeddings and the original text, providing a tunable hybrid search functionality.
- llama.cpp Server Container: Handles language model inference, generating responses based on data retrieved from Elasticsearch.
This modular architecture allows for scalability and adjustments, adapting to various hardware capacities.
Speed Metrics
To evaluate the performance of different models and context sizes, we developed a script that measures the text generation speed across various settings. The script includes templates for symptoms, conditions, and medications, each paired with base questions and additional context. This allows us to measure the generation performance with input contexts ranging from 100 to 1600 tokens, generating 200 output tokens in each case.
We evaluated our RAG implementation using three models and different quantization settings:
- Phi-3.5-mini-instruct-F16 (no quantization)
- Meta-Llama-3.1-8B-Instruct-F16-Q2_K (Q2 quantization)
- Meta-Llama-3.1-8B-Instruct-F16-Q5_K_M (Q5 quantization)
Key metrics analyzed included:
- Prompt processing time: Time taken to process input before token generation.
- Prediction time: Duration for generating output tokens.
- Tokens per second: Tokens generated per second.
For inputs of 400 tokens, the results on a Dell Inspiron 15 with integrated graphics, 12 cores, and 32GB of RAM and a MacBook Pro M1 with 10 CPU cores and 16GB of RAM were as follows:
Dell Inspiron 15:
- Prompt processing time: 37.4 seconds
- Prediction time: 53.8 seconds
- Tokens per second: 3.7
MacBook Pro M1:
- Prompt processing time: 10.05 seconds
- Prediction time: 10.2 seconds
- Tokens per second: 19.52
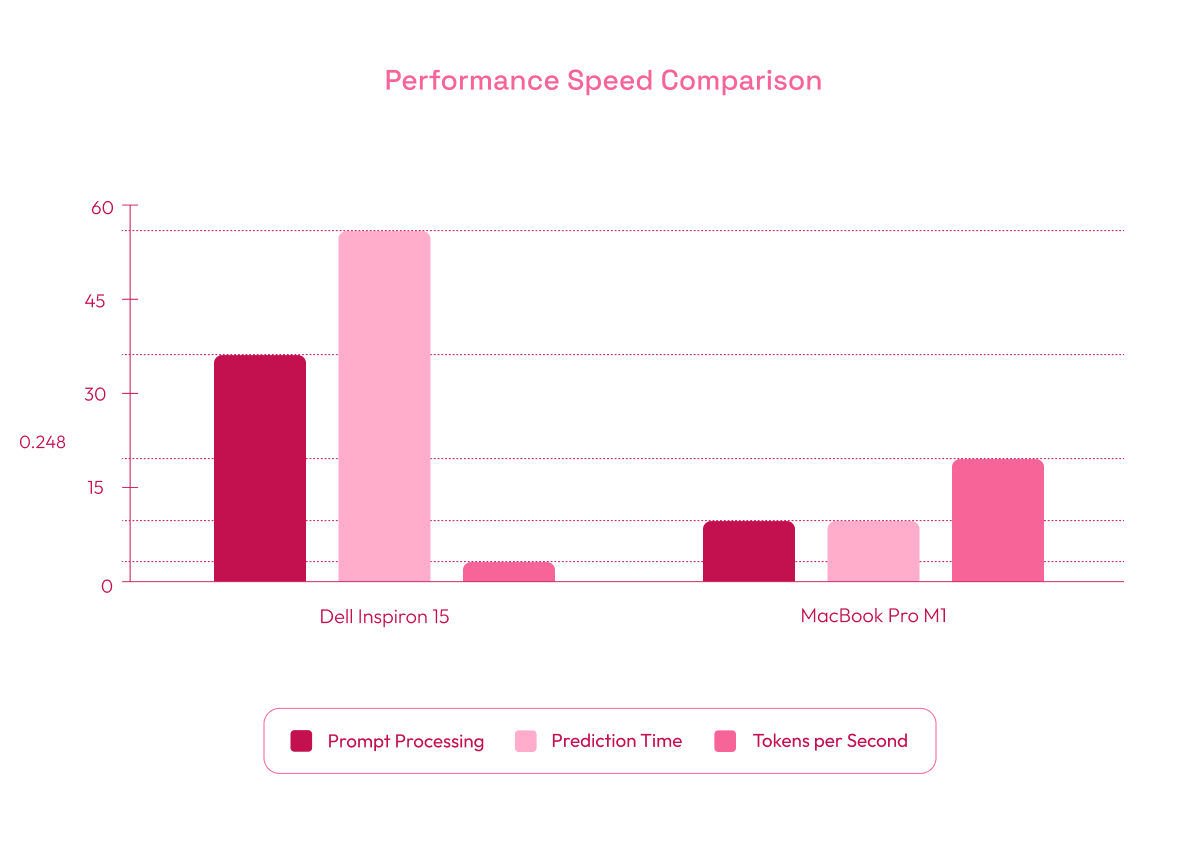
These results show the model's slower performance on limited hardware like the Dell Inspiron 15, while the MacBook Pro delivers significantly faster processing. This highlights the notable speed improvements that come with using more capable hardware, demonstrating the importance of selecting the appropriate environment to maximize llama.cpp's capabilities and achieve optimal performance in local RAG implementations.
Conclusion
While implementing a local RAG system with llama.cpp offers notable benefits, achieving optimal performance remains a challenge, especially when it comes to balancing hardware capabilities with model efficiency. Our results highlight that the choice of hardware significantly impacts response times and throughput—faster GPUs and newer CPUs deliver near-instantaneous results. At the same time, more modest setups may struggle to meet the demands of real-time applications.
The landscape of local AI execution is continuously evolving, with new models and hardware optimizations emerging regularly. These advancements gradually lower the barriers to achieving robust performance in local deployments, making it increasingly practical for organizations to adopt these solutions. While local setups may not yet match the scalability of cloud-based alternatives, their capabilities continue to improve, offering a compelling choice for use cases that prioritize data control and adaptability.
Navigating the challenges of hardware and model selection remains key to unlocking the full potential of local RAG systems, but the progress being made suggests a promising future for this approach.

