
Airflow introduced several changes in its second version a year ago. Since then we've had the opportunity to experience most of them. And we especially had a good time working with its new Taskflow API. After considering whether we should adopt this new feature, we finally decided to make Taskflow a part of our daily work. This blog post will show why you should too.
First thing's first, What's TaskFlow?
The Taskflow API is an abstraction built on top of XComs that allows developers to send messages between tasks in a DAG (Directed Acyclic Graph). It seems pretty straightforward, right? But it also comes with several tools to make our life easier, primarily if most of your DAGs are written as Python tasks. Let's dive into them with an example.
1) Creating DAGs with ease
Imagine you need to write an ETL process with Airflow to process sales information about our customers. The data comes from two different sources: a third-party CRM via a RESTfull API and an owned relational database. We want to process the information we've recovered from those two sources, unify the data's schema, and keep relevant information for us. Finally, we'd store the transformed data in persistent storage to be consumed later by the analysis team.
You can find the complete code on GitHub following this link.
The old way, DAG Definition before Taskflow
For our ETL process, we need to implement some tasks to get the data out of its source, transform it, and load it into the persistent storage. Traditionally, we'd write our DAGs following a structure similar to the one shown next:
def extract_from_api(**kwargs):
# TODO: Fetch the data from an API and store it where it can be
# read later
pass
def extract_from_db(**kwargs):
# TODO: Fetch the data from our database and store it where it can
# be read later
pass
def transform(**kwargs):
# TODO: Read the data extracted, transform it to fit our needs and
# then store it where it can be read later
pass
def load(**kwargs):
# TODO: Read the transformed data and save it where it can be analyzed later
pass
with DAG('awesome_etl_v1') as dag:
ext1 = PythonOperator(
task_id='extract_from_api',
python_callable=extract_from_api,
provide_context=True,
)
ext2 = PythonOperator(
task_id='extract_from_db',
python_callable=extract_from_api,
provide_context=True,
)
trn = PythonOperator(
task_id='transform',
python_callable=extract_from_api,
provide_context=True,
)
load = PythonOperator(
task_id='load',
python_callable=extract_from_api,
provide_context=True,
)
[ext1, ext2] << trn << loadWithout Taskflow, we ended up writing a lot of repetitive code. And this was an example; imagine how much of this code there would be in a real-life pipeline!
The Taskflow way, DAG definition using Taskflow
Taskflow simplifies how a DAG and its tasks are declared. This is done by encapsulating in decorators all the boilerplate needed in the past. Using these decorators makes the code more intuitive and make easier to read.
@task()
def extract_from_api():
# TODO: Fetch the data from an API and store it where it can be
# read later
return {}
@task()
def extract_from_db():
# TODO: Fetch the data from our database and store it where it can
# be read later
return {}
@task()
def transform(api_data, db_data):
# TODO: Read the data extracted, transform it to fit our needs and
# then store it where it can be read later
return {}
@task()
def load(data_to_load):
# TODO: Read the transformed data and save it where it can be analyzed later
pass
@dag(schedule_interval='@Daily')
def awesome_etl_v2():
data = transform(extract_from_api(), extract_from_db())
load(data)
etl_dag = awesome_etl_v2()Let's see what's new in the code above:
- The
@taskdecorator: turning a python function into an AirflowPythonOperatortask is as simple as annotating it with@task. Additionally, any value returned by one of these operators can be passed to another operator, making it really simple to send messages between tasks. We'll dig into this in the next section. - The
@dagdecorator: in a similar way, we can turn a python function into a DAG generator using this decorator. - Dependency inference: notice we haven't used either one of Airflow's dependency operators (
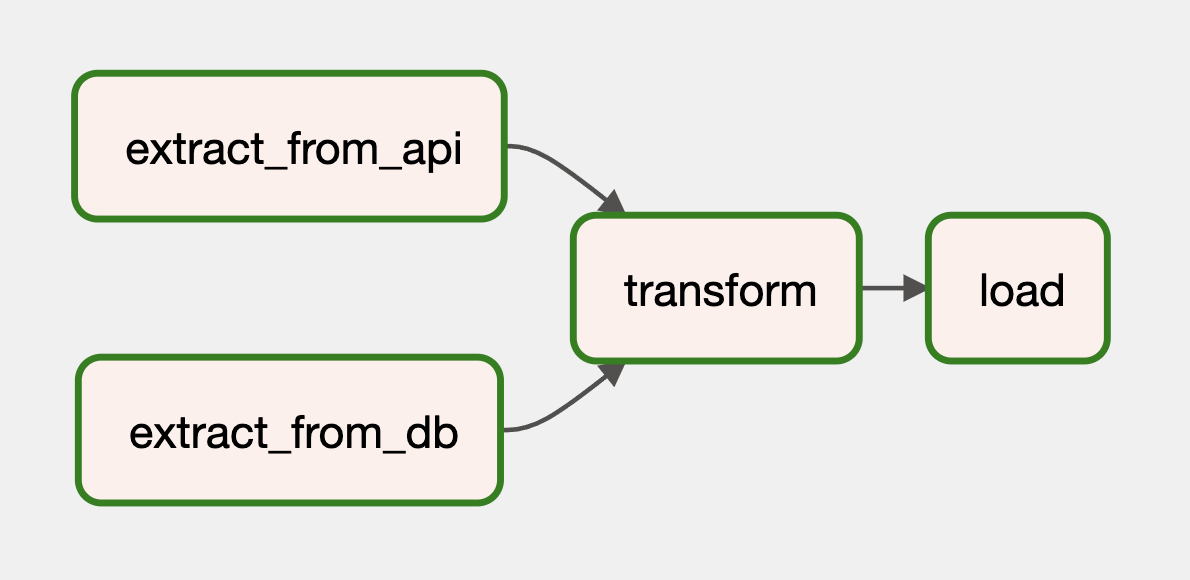
<<,>>). With Taskflow, Airflow can infer the relationships among tasks based on how their called. In the example above, Airflow determines thattransformdepends on bothextract_from_apiandextract_from_db. Analogously, Airflow determines theloadtask depends ontransform. And it's done automatically, sweet! This is how our DAG would look in Airflow's UI:
2) Simplified tasks communication
Tasks are isolated and can't share data as we typically do in Python code. We can only share information between tasks by using XComs.
To continue with our example, let's see how we can do this using the old API:
def extract_from_api(**kwargs):
json = ... # TODO: Fetch data from the API
# Store results in XComs to share, in a real world solution,
# a reference to the data should be returned here
task_instance = kwargs['ti']
task_instance.xcom_push(key='contacts', value=json['results'])
def extract_from_db(**kwargs):
data = ... # TODO: Fetch data from DB
# Store results in XComs to share, in a real world solution,
# a reference to the data should be returned here
task_instance = kwargs['ti']
task_instance.xcom_push(key='contacts', value=[row for row in data])
def transform(**kwargs):
task_instance = kwargs['ti']
# Read the results from previous tasks stored in Xcoms
api_data = task_instance.xcom_pull(key='contacts', task_ids='extract_from_api')
db_data = task_instance.xcom_pull(key='contacts', task_ids='extract_from_db')
# TODO: process the data and save the results
# ...
with DAG('awesome_etl_v1') as dag:
# ...
# Intentionally missed ext2 in the dependencies definition.
ext1 << trn << load| To have access to XComs, we need a task_instance, which is passed as an argument to the python functions referenced by the PythonOperator instances. task_instance provides xcom_pull and xcom_push to read and write argument values, respectively.
Reading a value from XComs written there by another task defines a dependency between those two tasks. However, they're not explicit, which makes it hard to see them as we'd need to dive into the DAG's implementation. Airflow won't infer those dependencies either, and we can't visualize them in the Graph view in Airflow UI. If we forgot to explicitly define it, either with >> or <<, Airflow won't guarantee the tasks will run in the appropriate order. This may cause runtime errors in our pipeline that would be hard to debug. This can be one of the most confusing parts of a DAG!
In the example above, I intentionally left the ext2 task out of the dependencies list of the trn task. And even the trn task is getting a value from XComs written by ext2, Airflow won't know about the dependency between those two tasks. As there's no explicit dependency between ext2 and trn, Airflow will execute trn as soon as ext1 has finished, regardless of the state of ext2. You see the race condition, right?
This is how this DAG would look in the Airflow Graph view:
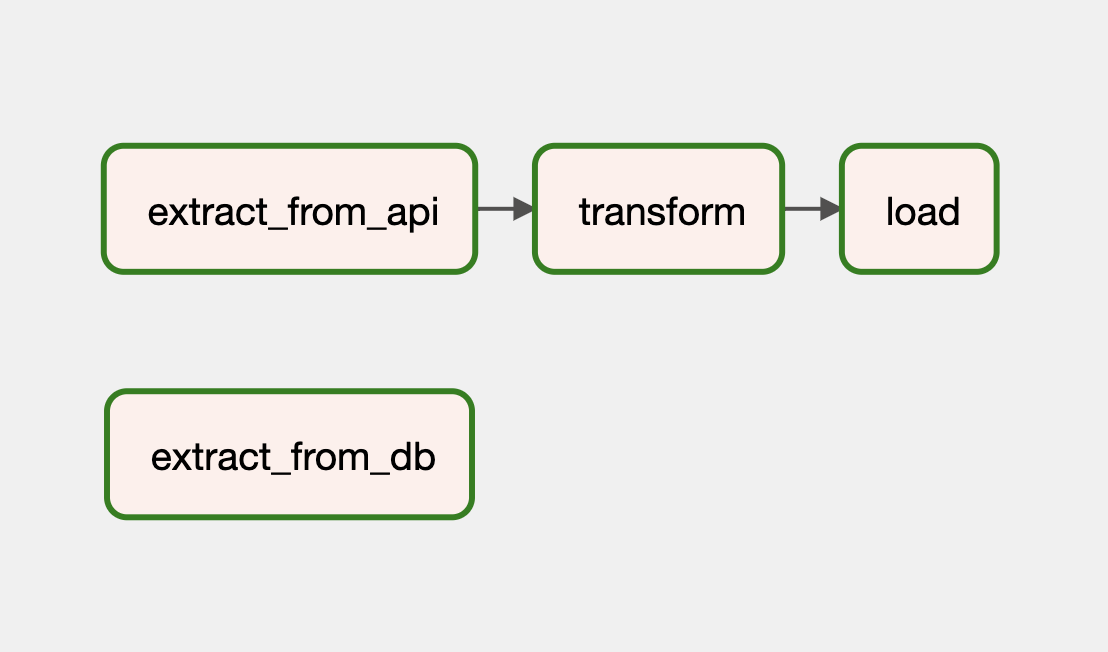
| The implicit dependency between extract_from_db and transform, based on XComs data sharing, is not expressed in terms of the graph.
With the new Taskflow, we can eliminate almost all the code involved in reading from and writing to XComs. The most significant advantage is Airflow will automatically infer dependencies!
@dag()
def awesome_etl_v2():
@task()
def extract_from_api():
json = ... # TODO: Fetch data from the API
return {'contacts': json['results']}
@task()
def extract_from_db():
data = ... # TODO: Fetch data from DB
return { 'contacts': [row for row in data] }
@task()
def transform(api_data, db_data):
api_data = api_data['contacts']
db_data = db_data['contacts']
# TODO: save the transformation result to disk.
return { 'output_file': '/awesome_etl/output/transformed_data.json' }
transform(extract_from_api(), extract_from_db())
dag = awesome_etl_v2()Any value returned by a PythonOperator task is automatically saved into XComs with the return_value key. To make usage of the stored values, the only thing we have to do is pass them as arguments to other python tasks, as shown in the call to the transform function.
As we mentioned before, Airflow infers the relationship between tasks based on the usage of their returned values. And those dependencies are explicitly expressed in terms of the graph. Now Airflow runs the transformation task right after both extraction tasks have been completed. No more race conditions!
3) Interoperability
A nice thing about these new features is that you can gradually adopt them into existing projects. There's no need to do an all-at-once migration. Existing PythonOperator tasks can be migrated to use the new @task decorator one at a time.
Next, we will migrate only extract_from_api and transform tasks from the example that does not use Taskflow to show how this works.
@task()
def extract_from_api():
json = ... # TODO: Fetch data from the API
return json['results']
def extract_from_db(**kwargs):
data = ... # TODO: Fetch data from DB
# Store results in XComs to share, in a real world solution,
# a reference to the data should be saved here
task_instance = kwargs['ti']
task_instance.xcom_push(key='contacts', value=[row for row in data])
@task()
def transform(api_data, db_data):
# TODO: process the data and save the results
return {}
with DAG('') as dag:
ext1_data = extract_from_api()
ext2 = PythonOperator(
task_id='extract_from_db',
python_callable=extract_from_db,
)
transform(ext1_data, ext2.output)| output is a property available for every operator, this means we can use it for every existing task in our DAGs.
As extract_from_api is using the new Taskflow API we can get rid of the XComs functions it was using and just return its output and assign it to ext1_data variable, which then is passed as an argument to the transform task. On the other hand, extract_from_db is still using the old API, and we can access the values it saves into XComs by accessing its output property without executing any of the XComs functions.
4) XComs custom backends
Even though XComs is what powers Taskflow up, it has it's own limitations. One of them is that only JSON-serializable values can be stored in XComs, this prevents us from storing custom classes instances. Moreover, those values are saved into Airflow's metadata database, limiting the size of the data we can store. These two points mean we can't save different types like numpy objects, dates, pandas data frames, etc., and we can't store values that are greater than 1 GB either.
This imposes some limitations to the data we can pass through our DAG's tasks. Luckily, using XComs custom backends, available Airflow version 2 and greater, gets rid of these limitations. This allows us to implement serializers to encode any object we need and save them to a destination of our preferences.
For example, we could save the DAG's XComs variables in a reliable and scalable low-cost cloud storage service as AWS S3. Additionally, we can save any encodable python type, like a pandas data frame. Let's see with an example how easy we can do both looking at the following code snippet:
from airflow.models.xcom import BaseXCom
from airflow.providers.amazon.aws.hooks.s3 import S3Hook
import pandas as pd
import uuid
class PandasToS3XComBackend(BaseXCom):
DATA_SCHEMA = "awesome-etl-s3://"
@staticmethod
def serialize_value(value):
if isinstance(value, pd.DataFrame):
from airflow.models import Variable
bucket = Variable.get('awesome_etl_bucket')
hook = S3Hook(Variable.get('awesome_etl_aws_connection_id'))
file_name = f'data_{str(uuid.uuid4())}.json'
key = f'{AWS_BUCKET_PREFIX}/{file_name}'
with open(file_name, 'w') as file:
value.to_csv(file)
hook.load_file(file_name, key, bucket, replace=True)
value = PandasToS3XComBackend.DATA_SCHEMA + key
return BaseXCom.serialize_value(value)
@staticmethod
def deserialize_value(result):
result = BaseXCom.deserialize_value(result)
if isinstance(result, str) and result.startswith(PandasToS3XComBackend.DATA_SCHEMA):
from airflow.models import Variable
bucket = Variable.get('awesome_etl_bucket')
hook = S3Hook(Variable.get('awesome_etl_aws_connection_id'))
key = result.replace(PandasToS3XComBackend.DATA_SCHEMA, "")
file_name = hook.download_file(key, bucket, "/tmp")
result = pd.read_csv(file_name)
return result
def orm_deserialize_value(self):
result = BaseXCom.deserialize_value(self)
if isinstance(result, str) and result.startswith(PandasToS3XComBackend.DATA_SCHEMA):
result = f'{result} (serialized by "PandasToS3XComBackend")'
return resultLet's quickly explain the code above. There are two main methods we have to implement for our custom backend:
serialize_valuereturns what's stored in the XComs' database registry. In our example, we only care about encodingpandasDataFrameinstances, in which case we serialize it as a CSV file and upload it to S3. Finally, we return the path to that file in S3, so later, when we need to get the original value, we can download the correct file and deserialize its content as the originalpandasDataFrame. Otherwise, we delegate the serialization job toBaseXCom.deserialize_valuetakes whateverserialize_valuereturned and returns back the original value. In our case, we determine whether the serialized value must be deserialized as apandasDataFramebased on the custom URI schema we used in the serialization's result. Otherwise, we letBaseXComdo its job.- finally, if we prefer, we can implement
orm_deserialize_valueto change how the serialized values are shown in Airflow's UI.
And this is how our custom XComs variables will look:
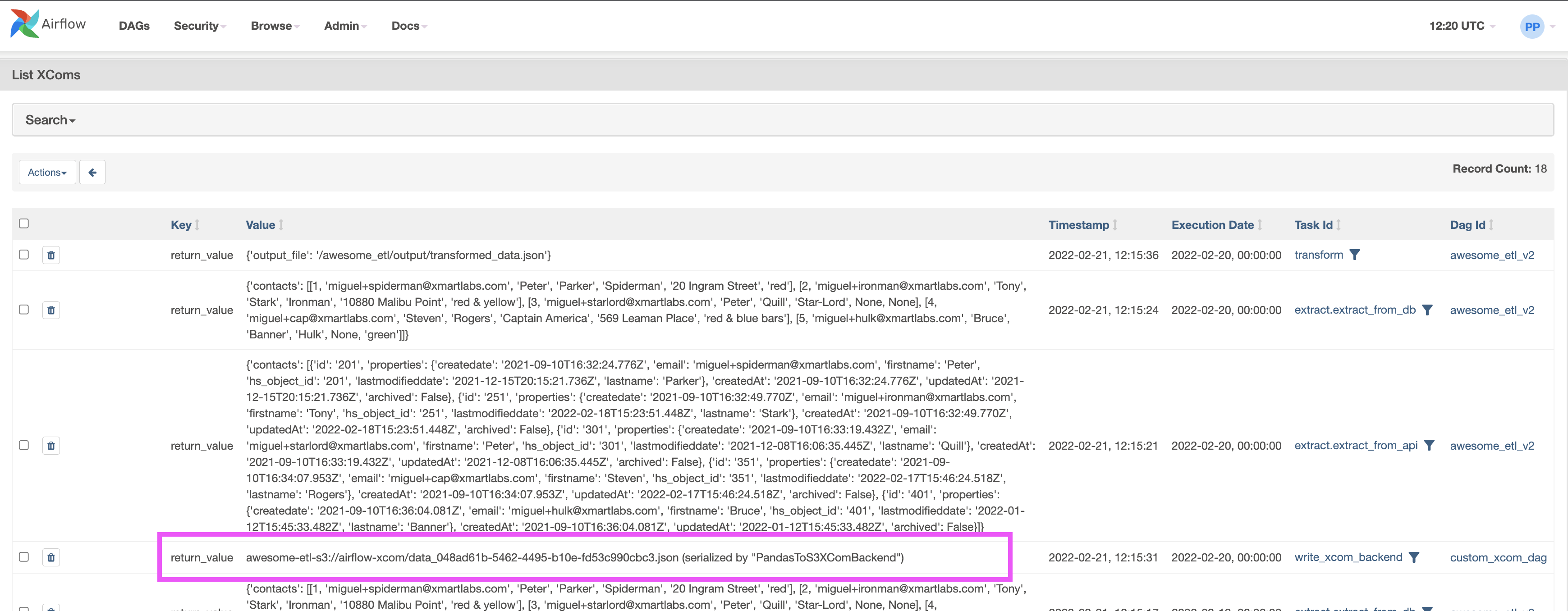
This gives us a lot of extra freedom. Even though, in theory, we could save a big chunk of information this way, it's not the idea to use XComs to support a data-driven pipeline. I mean, we should keep information backed up by XComs to small chunks as Airflow itself isn't designed to move much information.
Final thoughts
We have seen the advantages of implementing a DAG by using Taskflow.
- It reduces boilerplate code.
- Simplifies the tedious process of passing arguments among tasks.
- Infers task dependencies, and much more.
All these Taskflow features cut off development, maintenance, and ETL pipeline understanding time. Not to mention that is less prone to error.
The best part is there's much more to come, you can find these in the Airflow's git repository.
Thanks for reading! ❤️
Got stuck developing ETL solutions? We'd love to help! Get in touch to start leveraging the power of your data today!