


Introduction
In this digital age of endless possibilities and vast information, recommendation systems have emerged as the guiding compass that helps us navigate through the overwhelming sea of choices. Whether it's suggesting the perfect movie to watch, a personalized playlist for a road trip, or a tailored product recommendation, these intelligent algorithms have become integral to our online experiences.
Recommendation systems are normally composed of multiple models either by combining their outputs or chaining the models in a pipeline. It is common to have a retrieval model that selects a few hundred or thousands of candidates from the complete set and then run a ranking model on these candidates to rank them.
In this blog, we will focus on the retrieval model part, with special emphasis on encoding the user watch history with the help of LLMs. For an introduction to recommendation engines and their importance, check out our blog post on the matter.
Two tower retrieval models
Retrieval models should be fast to be computed on all items of a catalog and are often implemented as a vector search where the model returns the closest vectors (embeddings) to a given query.
A common model architecture that follows this pattern is the two tower architecture. One tower takes the user features and produces the user (query) embedding, while the other takes the item features to create an item embedding. The item embeddings can be computed offline and indexed for more efficient serving. This means that in inference time, you need only to compute the user (query) embedding and then find the closest embeddings from the index.
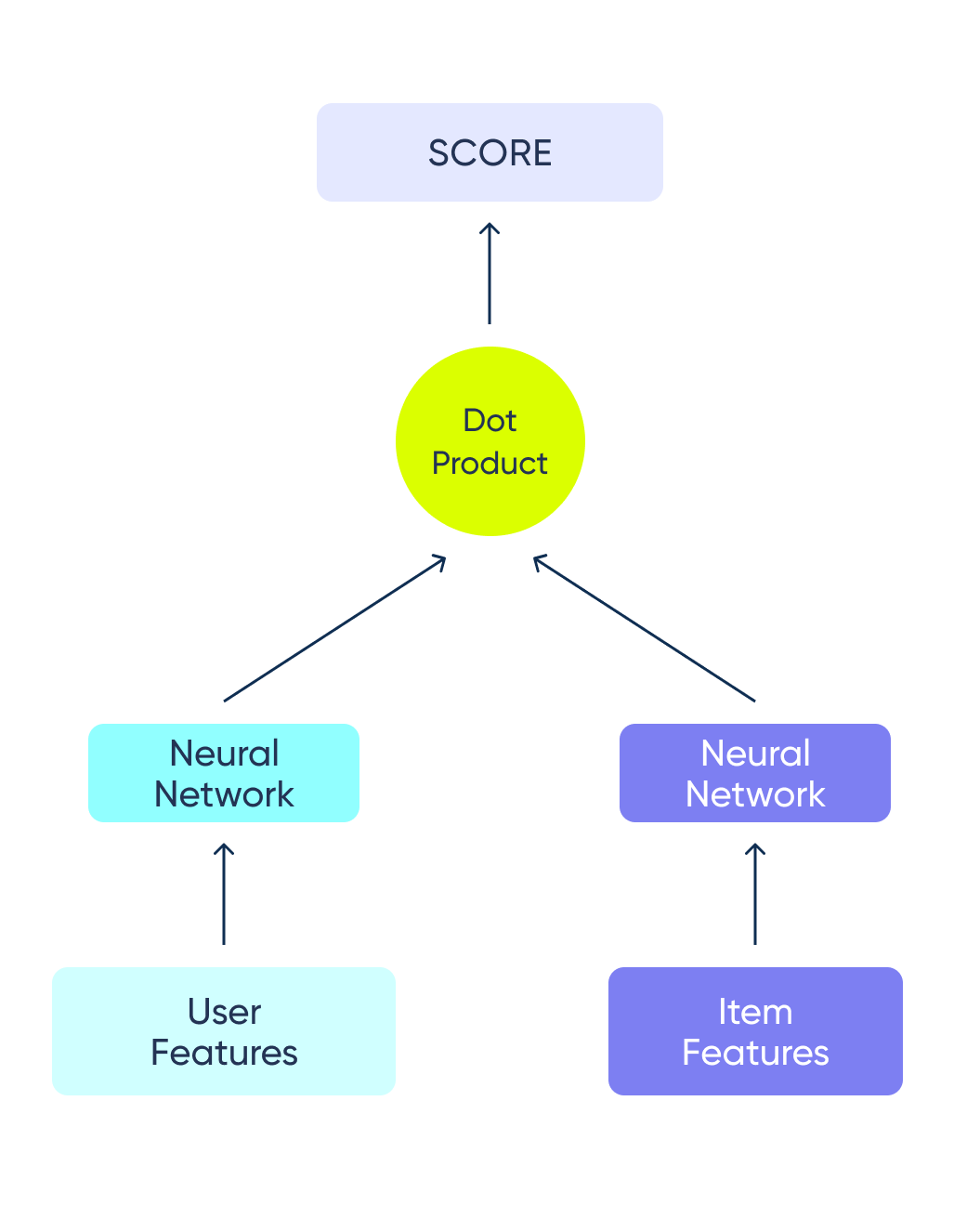
In this blog, we will show how to build the user tower using TensorFlow Recommenders, taking advantage of its scalability, flexibility, and community. If you haven’t already, check out the basic TensorFlow Recommenders tutorial, which will get you up and running with a basic retrieval model. We will delve into some more advanced preprocessing and model building. Specifically, using Open AI embeddings, attention layers, and more, showing the advantages of such an approach.
MovieLens dataset
One of the most commonly used movie datasets is the MovieLens dataset. It contains 25 million user ratings given by 162,000 users to 62,000 movies up until 2019. For each movie, it includes the title and genre, while for each user we just have a user ID. There is also a file that links each movie ID to the corresponding ID in popular movie webpages, TMDB and IMDb, from which we can obtain more metadata for these movies. To train our movie recommender, we used this dataset combined with input from TMDB.
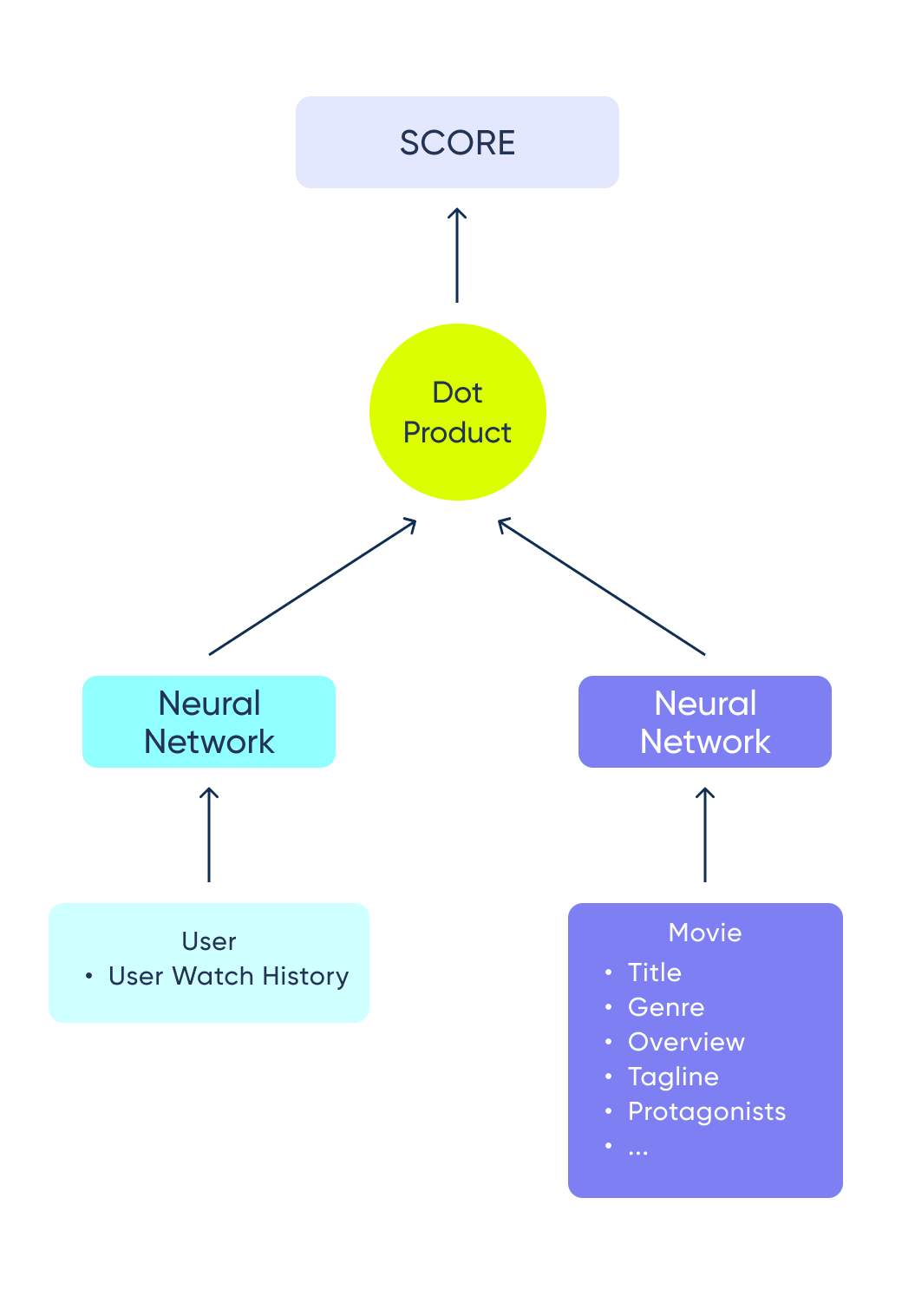
Using the movie metadata, we can create very rich item feature vectors. On the other hand, we don't have similar information about our users (such as age, gender, likes, and dislikes). We only have the user’s ID and the movies a user has watched as our user features. The watch history is what contains the most information about the user and is what lets us relate a specific user to other similar ones. But how do we use this information? One option would be to learn an embedding for each movie ID and then combine all the embeddings in a watch history and use that as input for the user tower. This has several drawbacks:
- Restricted to movies that are in the training dataset (in this case, movies older than 2019)
- The model has to learn these embeddings only by learning from interactions of similar users (collaborative filtering) and not from metadata of the movies. This metadata could be added as separate inputs, but the model still needs to learn these embeddings from scratch.
However, we can show you a better way of encoding this user watch history by leveraging the power of OpenAI’s embedding API, which will allow us to use embeddings of movies that are not in the dataset while also removing the need to learn these embeddings from scratch.
As for the user ID, it is possible to let the model learn an embedding for each ID. However, using the user ID means that you need to retrain the model for each new user in your system, while the watch history can be helpful after just a few user interactions, even without retraining the model. In addition, when the dataset you train on is not from your system (like in this case with the MovieLens dataset), the user ID will not be helpful to you at all. That’s why in this case, we didn’t use the user ID.
We split the dataset by users, taking a random set of 20k users as our validation dataset. This way, we can measure how well the model generalizes to users that are not in the dataset.
Leveraging LLMs to get movie embeddings
Using some of the columns of the movie metadata we can build a descriptive text for each movie like this:
Title: Star Wars: Episode I - The Phantom Menace.
Overview: Anakin Skywalker, a young slave strong with the Force, is discovered on Tatooine. Meanwhile, the evil Sith have returned, enacting their plot for revenge against the Jedi..
Tagline: Every generation has a legend. Every journey has a first step. Every saga has a beginning..
Genres: Adventure, Action, Science Fiction.
Protagonists: Liam Neeson, Ewan McGregor, Natalie PortmanWe can then use the OpenAI API to get an embedding, not only for the movies we have in the dataset, but also for newer movies, so as the user interacts with those movies, we can use their embedding in the model to get more accurate results. In this example, it lets us train a model which can recommend movies that were released after 2019.
Getting an embedding from OpenAI is pretty easy:
import openai
# You need to set the OPENAI_API_KEY env variable
def get_embedding(text):
text = text.replace("\n", " ")
return openai.Embedding.create(input=[text], model="text-embedding-ada-002")['data'][0]['embedding']This can be extended to get embeddings for all movies and arrange these vectors in a 2D numpy matrix.
To validate that OpenAI’s embeddings actually capture the information about a movie, we can query which are the closest embeddings to a query vector. For example, which embeddings are closest to the embedding for the Toy Story movie, using cosine distance:
Toy Story 3 => Distance: 0.0617431402206
Toy Story 2 => Distance: 0.0669441819191
Toy Story 4 => Distance: 0.0801900029182
Toy Story of Terror! => Distance: 0.0992990136147
Buzz Lightyear of Star Command: The Adventure Begins => Distance: 0.104605972767
Beyond Infinity: Buzz and the Journey to Lightyear => Distance: 0.112128674984
Lightyear => Distance: 0.114516556263
Toy Story That Time Forgot => Distance: 0.125901699066
Lamp Life => Distance: 0.132924675941This shows that the closest embeddings are actually very similar movies and, thus, that the embeddings capture meaningful information.
Integrate embeddings into user tower
To integrate the embeddings we got from OpenAI into the model, we can use TensorFlow’s tf.keras.layers.Embedding layer and pass the embeddings to the initializer:
embedding_matrix = ... # 2D np.array
num_tokens = ... # number of movies we want to support + 1 for unknown movies
embedding_layer = Embedding(
input_dim=num_tokens,
output_dim=embedding_matrix.shape[1], # vector dim = 1536 in case of OpenAI embeddings
embeddings_initializer=tf.keras.initializers.Constant(embedding_matrix),
trainable=False,
)We can actually choose to initialize this embedding layer with OpenAI’s embeddings and then finetune them (by setting trainable=True). In our case, we found that not finetuning them worked better. This also has the benefit of speeding up training as these embeddings are given and not trained, so there are fewer parameters for the model to optimize.
We tracked all our experiments using a self-hosted instance of the open-source ClearML experiment tracking tool. Tracking experiments in a clear and reproducible way is essential in any ML project. It allows us to look back at the ideas we tried, some of which were discarded, and others became part of the final solution.
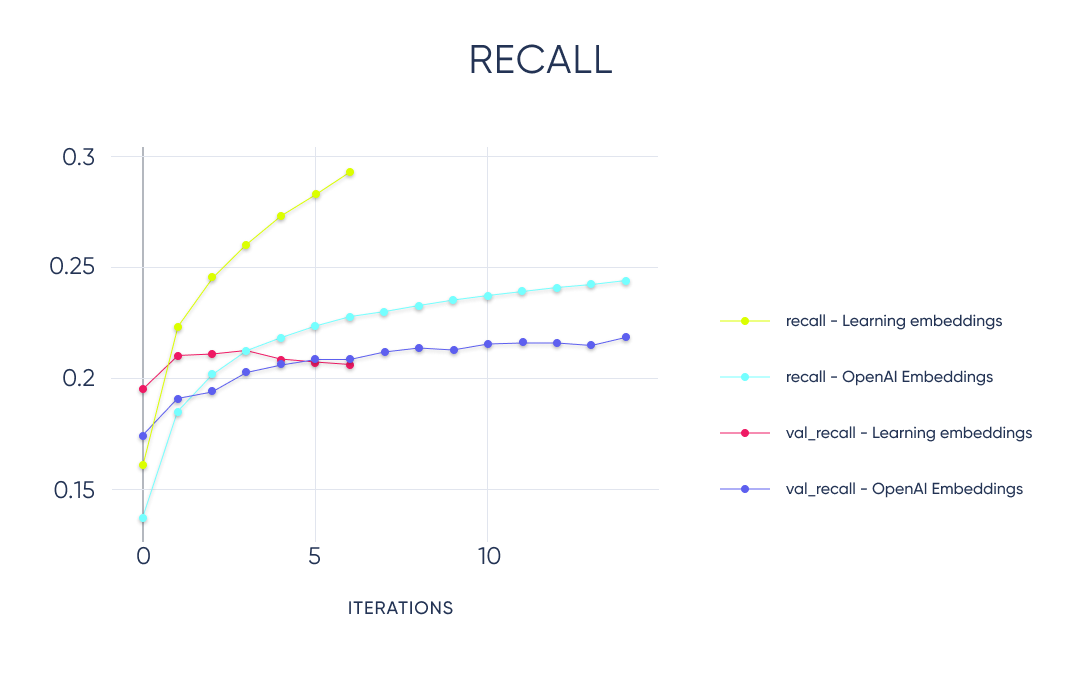
In this chart, we can see the difference between learning the embeddings and using the OpenAI embeddings. The biggest difference is that using OpenAI embeddings, the model generalizes better, but it also performs slightly better than when learning the embeddings from scratch.
Paying Attention to each other
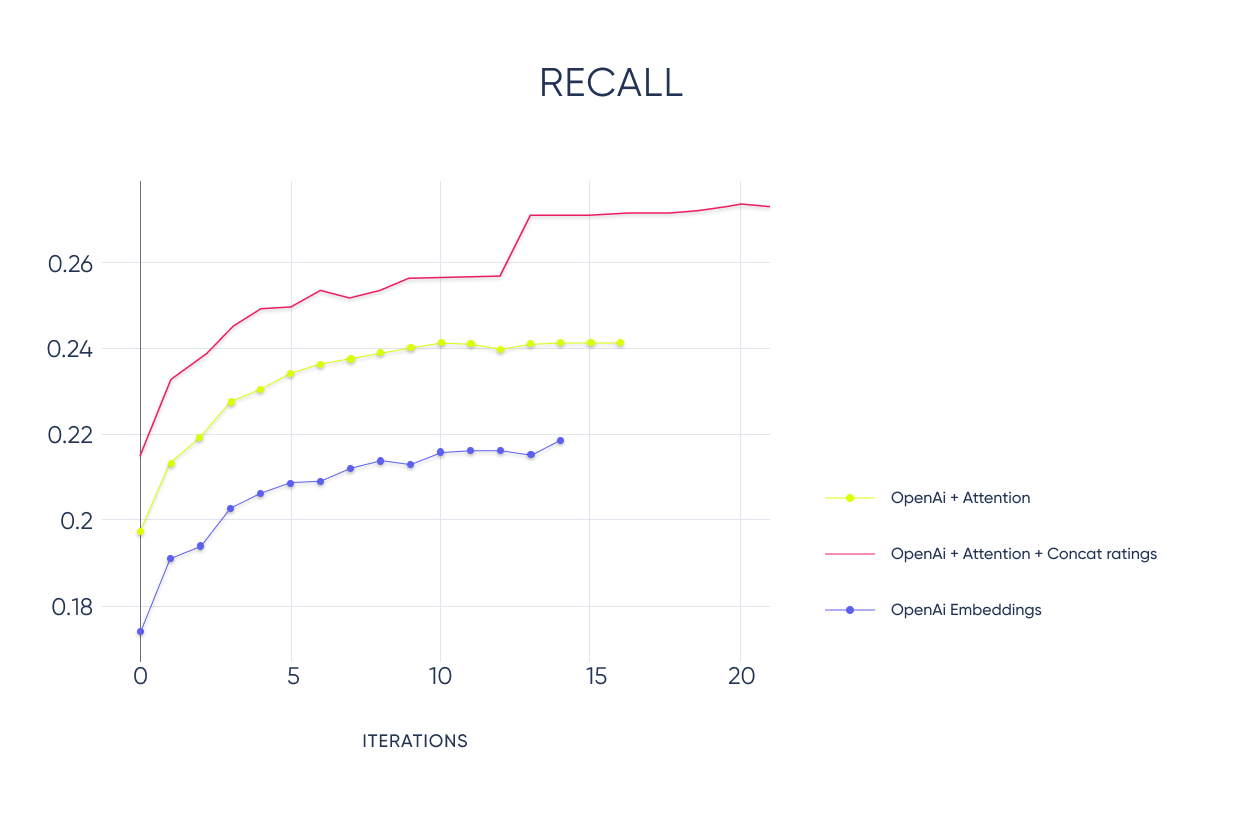
We found that adding a multi-head Self-Attention layer on top of the Embedding layer lets the model learn a much better user embedding. This can be done using the tf.keras.layers.MultiHeadAttention layer and passing the input tensor as both key and query parameters. See the results comparing a model with and without Attention below.
Combining embeddings
The result of the embedding layer will be a Tensor of dimension [B, None, 1536] where B is the batch size and the middle dimension is the number of movies in the user watch history. It is undefined as each user can have seen a variable number of movies. The size of OpenAI’s embeddings is 1536. The same shape will also be returned by the Attention layer.
We need to combine these embeddings to end up with a 2-dimensional fixed-size matrix of [B, 1536]. This means combining the values corresponding to each movie in the watch history post-attention layer to get a single vector. For this, we can now use something like GlobalAveragePooling1D or GlobalMaxPool1D, after which we will end up with the desired 2D Tensor. It is worth trying both of them or even similar layers. In our case, we went with the Average Pooling as the model is more capable even though it overfits a bit more than using the MaxPool.
After this layer we can add a couple of fully connected (Dense) layers, which will form our user tower and result in the final user embedding.
Adding user ratings to their embeddings
We found that adding the rating the user gave to each movie in the user's watch history can improve the model further. A simple but effective way to do this is to concatenate the rating to the embedding of the movie before applying the Attention layer. We actually calculate the average rating of the user’s watch history and subtract that from the rating of each movie to get values around 0. We then use tf.concat([embedding, rating], axis=-1).
We found this to work pretty good. As you can see in the chart, this will considerably increase the model’s recall.
Summary of user tower
Putting all of this together leaves us with a user tower as follows:
________________________________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
========================================================================================================================
user_history (InputLayer) [(None, None)] 0 []
lookup_user_history (IntegerLookup) (None, None) 0 ['user_history[0][0]']
history_ratings (InputLayer) [(None, None)] 0 []
user_history_emb (Embedding) (None, None, 1536) 25744896 ['lookup_user_history[0][0]']
tf.expand_dims (TFOpLambda) (None, None, 1) 0 ['history_ratings[0][0]']
tf.concat (TFOpLambda) (None, None, 1537) 0 ['user_history_emb[0][0]', 'tf.expand_dims[0][0]']
multi_head_attention (MultiHeadA... (None, None, 1537) 6300161 ['tf.concat[0][0]', 'tf.concat[0][0]']
global_average_pooling1d_4 (Glob... (None, 1537) 0 ['multi_head_attention[0][0]']
dense (Dense) (None, 128) 196864 ['global_average_pooling1d_4[0][0]']
dropout (Dropout) (None, 128) 0 ['dense[0][0]']
dense_1 (Dense) (None, 32) 4128 ['dropout[0][0]']
=======================================================================================================================
Total params: 32,246,049
Trainable params: 6,501,153
Non-trainable params: 25,744,896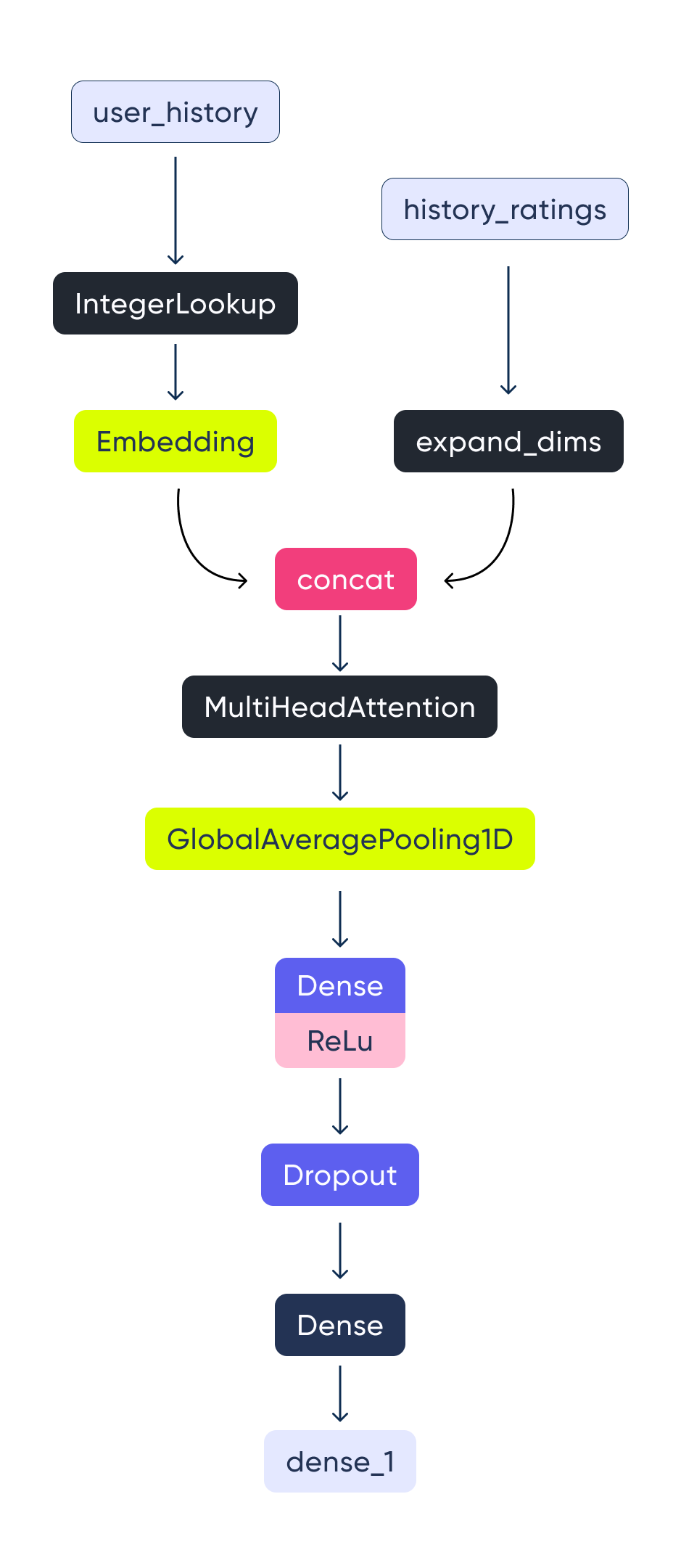
Conclusion
In this blog post, we demonstrate how to build a user model using a two-tower architecture that integrates external embeddings. This approach enables support for movies not present in the training dataset, while simultaneously improving model training. We also showed several additions on top of this model to improve its metrics significantly.
We have not talked about the other half of the two-tower model: the movie model. We might write about that in the future, so let us know if you would like to hear about it!
Want a powerful recommender model for your own business? Our experts specialize in developing tailored recommendation systems that drive engagement and boost revenue. Contact us today to discuss your needs, and we'll become your trusted partner in creating a personalized solution.

