


In a previous post, we covered computer vision and its application to body detection. Today, we’ll go a little bit deeper into the object detection problem showing an actual use case scenario: Lanthorn.
What's Lanthorn?
Lanthorn is an Occupancy Analytics product born during the Covid-19 pandemic as an Edge AI/ML solution to guarantee social distancing and facemask usage in shared spaces. Contrary to other solutions that involve buying sensors or hiring people to oversee social distancing, Lanthorn's solution uses existing video camera systems and applies ML models to guarantee the application of safety and sanitation protocols and keep spaces safe.
Lanthorn's support of several devices and edge deployment that ensures data security and privacy compliance make it a perfect solution for several use cases. This is why, after two years of constant development, and with the end of the pandemic nearing, we changed Lanthorn's product vision. We turned it into a complex occupancy analytics solution.

To pivot the product, we included new metrics such as room occupancy, counter for people going in and out of a building, calculations for dwell time or amount of people in specific regions, etc.
With these new metrics, Lanthorn managed to extend its original use case of space safety to others such as cost-saving, queue management improving, tailgating, and crowding detection. More importantly, all that was built using the original foundations: state-of-the-art object detection models.
Video analytic’s privacy issue
One of Lanthorn's main concerns was to protect users' privacy since, to gather analytics, Lanthorn consumes data from security cameras. With the privacy issue in mind, we built the solution using a hybrid approach, with a cloud server responsible for generating and distributing the metrics and multiple local nodes of processors (OSS software available in https://github.com/neuralet/smart-social-distancing) devices responsible for the video processing.
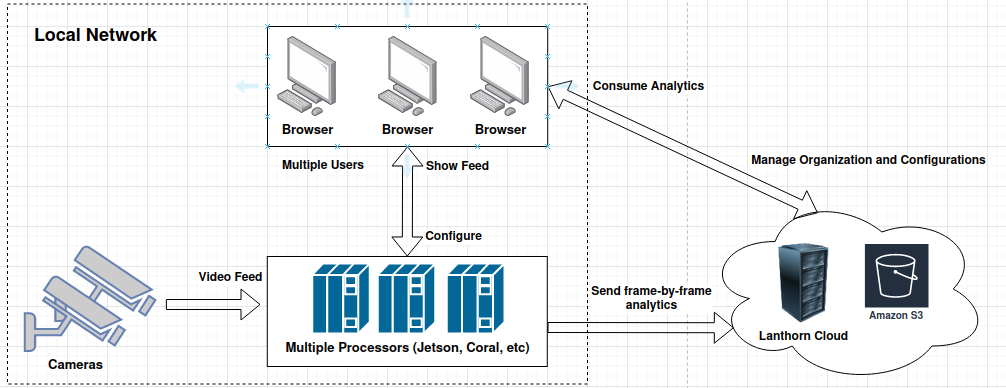
In this architecture, each user has the possibility of running the video processing within their LAN, without exposing any data to the outside; only numerical information is sent to the cloud backend, which ensures the privacy of the video's feed (It doesn't get exposed outside the camera's LAN). However, the disadvantage is that each user needs to acquire and configure the hardware required for executing that processing, and it's well known some ML solutions require specialized hardware (GPUs, TPUs, etc.) to perform efficiently, especially for video processing.
Why Object Detection in Lanthorn?
You’re probably wondering “Why are we talking about an occupancy analytics product in an Object Detection blog?” Well, because we’re interested in the way the product calculates metrics. Instead of building a specific end-to-end ML model for each metric, Lanthorn only has basic ML models (such as object detection) and computing analytics in post-processing.
Let's overview this architecture with a specific metric like social distancing. Rather than building an end-to-end neural network that, given a video frame, returns distances between people or which people are violating it; Lanthorn executes an object detection model (such as yolo) in a LAN’s processor and sends the detected people (bounding boxes) to the cloud’s backend. Here, the post-processing computes the social distancing violation using heuristics to measure distances from a flattened 2d coordinate system.
This approach presents many advantages:
- There’s no need for training customs models. Moreover, as the main ML component in the solution is the object detection party, Lanthorn can use already built, state-of-the-art, person detectors.
- The model’s accuracy improves with the state of the art. When a new person detection model is published, it can be integrated as a module on Lanthorn, without development or re-training effort.
- Adding new metrics is easy. Including a new metric for the product only involves implementing the post-processing logic. There's no need to re-train any ML model. Moreover, it's possible to calculate the new metric for historical data without re-processing the videos.
- The customer doesn’t need expensive infrastructure to run Lanthorn. There are already implemented person detection models built to run efficiently in low-resource devices; allowing to run Lanthorn in edge devices such as NVIDIA Jetson Nano, Coral Dev Board, Coral USB Accelerator, etc
Object Detection models diversity in Lanthorn
Considering the diversity of devices and uses cases that Lanthorn supports, there isn't a unique model that suits all the scenarios. The models can vary depending on the number of cameras, the granularity of the metrics, and the desired alerts.
- NVIDIA Jetson Nano
- NVIDIA Jetson TX2
- Coral Dev Board
- AMD64 node with attached Coral USB Accelerator
- X86 node
- X86 node accelerated with OpenVino toolkit
- X86 node with Nvidia GPU
Devices Lanthorn supports. So many devices usually mean diverse use cases.
Imagine, for example, a user interested in using Lanthorn to monitor the time people spend lining in a food track. In this case, the accuracy may not be important because you are not worried about detecting 100% of the people in the scene; but real-time metrics are key for taking action immediately after a delay is detected.
On the other hand, imagine someone is interested in using it to measure the occupancy of a building. In that case, the real-time metrics are not that important because the customer is more interested in stats (such as time of the day with max. occupancy, most used door, etc.). However, to make meaningful decisions, the quality of the analytics matters, so accuracy is essential.
Below, we'll list the different object detection models currently used in Lanthorn, along with their advantages.
MobilenetSSD
MobilenetSSD is an object detection model that belongs to the Single-Shot Detector (SSD) family and uses Mobilenet as its backbone. This makes it fast at object detection optimized for mobile devices. Before going deeper into that model, let's define what an SSD model is.
Single-Shot Detector (SSD)
The SSD model was published in the 2016 paper SSD: Single Shot MultiBox Detector. Before SDD, the most famous state-of-the-art object detection models follow a Two-stage object detectors architecture. This architecture (as his name indicates and we explained in our previous blog) needs two phases to detect a category in an image. In the first phase, the model detects the candidate regions where the objects can be located using some heuristic or specific CNN neural networks. Later, using the previously calculated regions as input, another model (the classifier) classifies each of these regions into the supported categories. These characteristics make these models very accurate and precise. However, they have the disadvantage of performing very slow on embedded systems. As mentioned in the SSD paper, the fastest implementation of these algorithms (Faster R-CNN) only archives seven frames per second (FPS).
Examples of two-stage object detectors algorithms are:
- R-CNN
- SPP-Net
- Fast R-CNN
- Faster R-CNN
- Cascade R-CNN
Despite its disadvantages, the SSD architecture contributes to the industry with the following characteristics:
- Faster solution than the previous state of the art for single-shot detectors (YOLO), and significantly more accurate. Some new models achieve the same accuracy as slower techniques that perform explicit region proposals and pooling (like Faster R-CNN).
- The core of SSD is predicting category scores and boxing offsets for a fixed set of default bounding boxes using small convolutional filters applied to feature maps.
- The model produces predictions of different scales from feature maps of different scales and explicitly separates predictions by aspect ratio to achieve high detection accuracy.
- These design features lead to simple end-to-end training and high accuracy, even on low-resolution input images, further improving the speed vs. accuracy trade-off.
Speaking of the model, the SSD architecture is based on a feed-forward convolutional network that produces a fixed-size collection of bounding boxes and scores for the presence of object class instances in those boxes, followed by a non-maximum suppression step to produce the final detections. The following image shows a graphical representation of the SSD architecture.
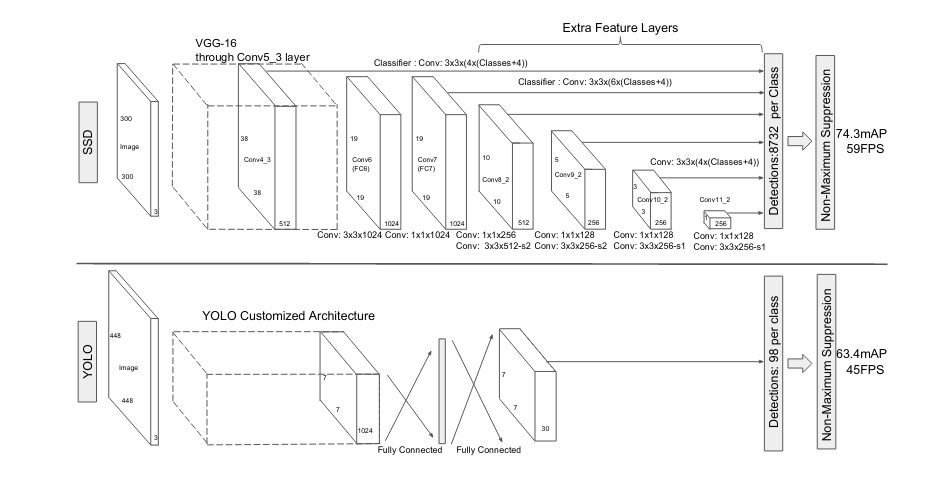
Mobilenet
The Mobilenet architecture was introduced in a 2017 paper (MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications). The publication mentions that, since AlexNet popularized deep convolutional neural networks by winning the ImageNet Challenge, more networks using these kinds of layers emerged. However, most of these proposals focused on improving the accuracy, ignoring the speed and size, which made them interesting for academic purposes but not useful for real-time applications.
Mobilenet is an efficient network architecture and a set of two hyper-parameters in order to build small, low latency models that can be easily matched to the design requirements for mobile and embedded vision applications.
The central concept behind x Mobilenet architecture is the depthwise separable convolution. It's a form of factorized convolutions that factorizes a standard convolution into a depthwise convolution, and a 1×1 convolution called a pointwise convolution. This change reduces considerably the number of parameters that a traditional convolutional network has, making the Mobilenet networks smaller and thus faster than the other models. Moreover, considering the proposed changes apply to convolutional layers, this architecture can apply to most of the implemented computer vision solutions.
Mobilenet SSD in Lanthorn
Bearing in mind the characteristics of the SSD neural networks and the Mobilenet architecture, it's pretty apparent that it's a perfect suit for Lanthorn. The high performance of the SSD allows real-time detection on video, an essential characteristic in the alerts feature. Moreover, the Mobilenet networks are small-sized, fundamental for devices with low resources, such as the edge ones supported by Lanthorn.
In addition to the previous comment, Mobilenet SSD has the advantage of possessing multiple implementations already built for most of the Lanthorn-supported devices. Many of these implementations are optimized for the device and support several sizes, allowing different configurations. For example, the coral suite has a public repository where you can download and easily use optimized models for those edge devices. In the Object Detection section, you can find the Mobilenet SDD and other object detection ones. There's also a repository with openvino pre-trained models with some versions (v1, v2) of Mobilenet SSD. If you have an X86 pc or a server with GPU, you'll probably use some of the already-built TensorFlow models that are available here.
With Lanthorn, some of the models used were created by the Neuralet team and are available in their public repository https://github.com/neuralet/models. These models are good for Lanthorn because each is optimized for the main devices supported by the product (jetson, coral, x86, gpus) as well as having different versions of Mobilenet SSD (v1, v2, pedestrian, and lite). You can choose the model that best fits your use case. For example:
- mobilenet_ssd_v2 with a high resolution can be used when high accuracy is desired.
- A lighter model can be chosen if you don’t have much computing power but still need high performance.
- If your use case involves people that are walking (e.g. a street camera), a model trained with the Oxford Town Center dataset can be selected, which performs better on that case than the model trained on COCO.
- mobilenet_ssd_v2 with a high resolution can be used when high accuracy is desired.
- If you don't have much computing power, you can choose a lighter model but need high performance.
- If your use case involves people walking (e.g., a street camera), a model trained with the Oxford Town Center dataset can be selected, which performs better on that case than the model trained on COCO.
YOLO
YOLO (acronym of You only look once) is a state-of-the-art, real-time object detection system that's very popular in the object detection industry. The 2016 paper "You Only Look Once: Unified, Real-Time Object Detection" first proposed the model, going on to win the OpenCV People's Choice Award that year.
Nowadays, detection systems repurpose classifiers to perform detection. Before the YOLO proposal, most object detection solutions took a classifier for that specific object and evaluated it at various locations and scales of the image. For example, deformable parts models (DPM) use a sliding window approach where the classifier is run at evenly spaced locations over the entire image. These pipelines are complex, slow, and hard to optimize because you must train each individual component separately.
YOLO took a completely different approach. Instead of executing a whole pipeline of individual components, it runs a single straightforward pass. It takes the reframe object detection as a single regression problem, straight from image pixels to bounding box coordinates and class probabilities. It's a single convolutional network that simultaneously predicts multiple bounding boxes and class probabilities for those boxes. YOLO trains on full images and directly optimizes detection performance.
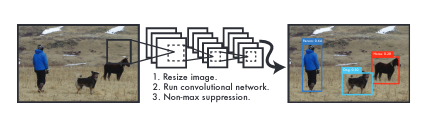
Compared with other alternatives, the YOLO model has some advantages:
- Yolo is fast. Since frame detection is a regression problem, there is no need for a complex pipeline. According to the paper, they will obtain over 150 fps performance in a Titan X GPU without sacrificing precision.
- YOLO learns generalizable representations of objects. YOLO outperforms top detection methods like DPM and R-CNN by a wide margin when trained on natural images and tested on artwork. Since YOLO is highly generalizable, it's less likely to break down when applied to new domains or unexpected inputs.
Pose estimation models
Although this is an object detection blog, you can use any pose estimation model for object detection tasks. As we explained in our previous blog, the pose estimation tasks detect the skeletons of the humans present in the image. Using that information, it's possible to rebuild the bounding box and obtain the same result as an object detection model (except for the person category).
We won't go too deep into the topic in this post, but to sum it up, most pose estimation models tend to be slower than object detection. That's because the pose estimation problem is more complex and requires higher resolution work.
In Lanthorn, the pose estimation models supported are openpipaf (https://github.com/openpifpaf/openpifpaf) and posenet (https://github.com/tensorflow/tfjs-models/tree/master/posenet).
Model comparison in Lanthorn
Okay, now that we know all the devices and deep learning models Lanthorn supports. Which one should you use? Well, the answer is: it depends 😃. You need to consider the type of metrics you want to measure, the chosen device, the number of cameras, etc. The best model for your use case can vary.
For example, let's talk about performance. The following table shows the measured FPS (frames per second) of the execution of some models varying some hyper-parameters and the device. The table shows the results of the previously discussed models (yolo and Mobilenetssd).
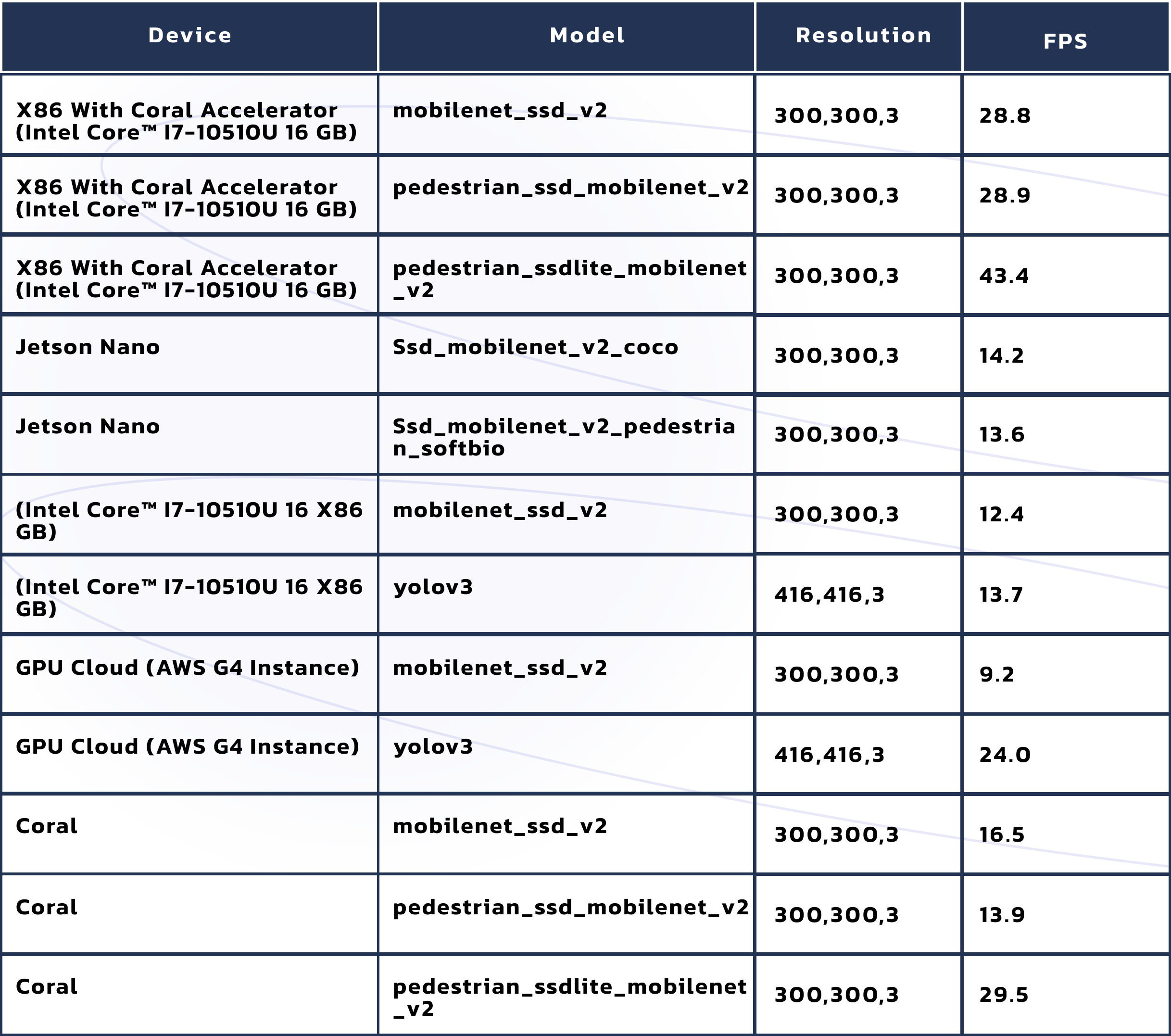
We can also include some pose estimation models.
| Device | Model | Resolution | FPS |
|---|---|---|---|
| X86 with Coral Accelerator (Intel Core™ i7-10510U 16 GB) | posenet | 481,353,3 | 13.4 |
| GPU cloud (AWS G4 instance) | openpifpaf optimized with tensorrt | 641,369,3 | 19.3 |

In Lanthorn, to have real-time metrics and alarms, you'll require at least 5 FPS per camera; otherwise, you will be losing some frames and their corresponding data. So, the number of cameras that you want to process and the chosen device can determine which model you need to use. For example, suppose you have only an X86 machine available, and you want to process more than three cameras. This scenario is not doable because the better-performing model for this device only achieves 13 FPS per camera. However, with the affordable Coral Accelerator (in the order of 70 dollars), you can manage six video inputs simultaneously.
This table also shows the performance gap between the object detection and the pose estimation models. As you can see, the pose estimation models are slower than the object detection ones, being up to twice times slower as the case of the accelerator. That means that if you're not interested in the metrics that require pose estimation models (such as facemask usage), it's better to use only object detection models and have the possibility of processing more cameras.
Another fact that the table shows is the excellent performance of Mobilenet architecture in edge devices. For example, in an X86 machine, the performance between yolov3 and Mobilenetssd is pretty similar. However, in edge devices (such as jetson and coral), the yolo doesn't perform well (for that reason is not supported by Lanthorn). Still, the Mobilenet performs very well without the need for high resources.
Another comparison between the models we can highlight is regarding the accuracy reached by each of them. The traditional way of model comparison in the object detection topic is the mean average precision (mAP). Considering that the models Lanthorn uses are well known and popular in the industry, you will find multiple tables comparing them. For this post, we took a different approach and compared them using one of Lanthorn's most used metrics by real state managers clients, the in/out metric. That metric "draws" a line in the door where the camera is pointing and counts the person who crosses this line.
This table shows the calculated number for the in/out metric put up against the real numbers (manually counted) for five videos clips of 1h duration. Similar to the performance table, we show the results for Lanthorn object detection models and one pose estimation (in italics).
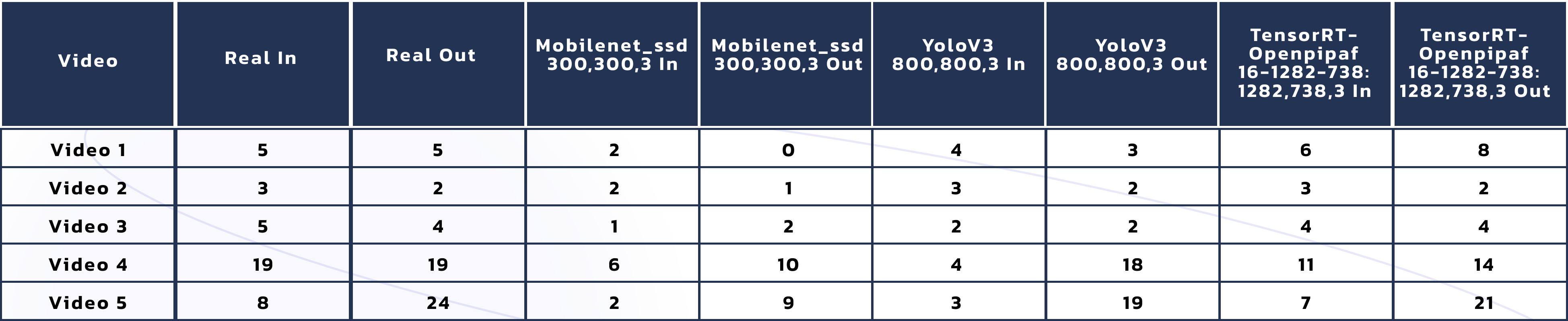
Well, let's analyze that table for a bit. The main thing that we can find is that the model with higher accuracy is openpipaf. We could expect this for several reasons. First of all, this model is pose estimation, which tends to be more accurate than the object detection models. Moreover, the resolution of that model is higher than the others, making it more precise. If we compare yolo and Mobilenet, we'll notice that yolo performs better. However, this is not a fair comparison because the resolution of both models is not the same.
Another fact to balance is the available resources required for each model. Looking only at the performance table, you can be tempted to choose the TensorRT model without any discussion. However, you will need a machine with GPU to use that model. Meanwhile, yolo can be executed in a single x86 one.
To sum up
On this blog, we concluded (with an actual use case example) that it's possible to build complex analytics metrics using video inputs with no need to design new machine learning models. With an architecture similar to Lanthorn, you can obtain creative and innovative solutions using already-build models. Today we focused on object detection models and some uses case, but you can apply this pattern to other solutions.
We can also conclude that choosing the model that better fits your circumstances is not a trivial decision. You can make multiple comparisons between two models, but it's essential to choose the one that will find the best possible solution. It's critical to have an in-depth understanding of the particularities of your use case before selecting a model. As was shown in the models' comparison sections, the best model can vary depending on your needs.
Finally, the machine learning models have improved a lot over the recent years, making it possible to execute video models in edge devices without sacrificing accuracy efficiently. This improvement facilitates the build of ML solutions without the need for expensive hardware, making possible the application of ML solutions in practical problems like Lanthorn.ai, as well as many others.
ML solutions have been proven to solve different issues and optimize processes in an array of different industries, especially traditional ones.
If you’d like to learn how our Machine Learning expertise might help you improve and optimize your business, whatever it is, contact us for a free discovery call with our experts.
Thanks for reading 🙂

