

Machine Learning
Deploying a Recommendation system using FastAPI, TF Serving and Feast

Introduction
In today's fast-paced and highly competitive business landscape, staying ahead of the curve is not just a goal but a necessity for success. With the exponential growth of online platforms and the overwhelming amount of information available, businesses face the daunting task of capturing and retaining the attention of their target audiences.
This is where recommendation systems come into play, offering a game-changing solution that revolutionizes how businesses engage with their customers. By leveraging cutting-edge algorithms and data analytics, recommendation systems have become essential tools that empower modern businesses to deliver personalized experiences, enhance customer satisfaction, and ultimately drive revenue growth.
Recommendation systems typically consist of multiple models, which are either composed by combining their outputs or chained in a pipeline. One common approach involves having a \*\*retrieval model\*\* to select a subset of several hundred or thousand candidates from the entire set. Subsequently, a \*\*ranking model\*\* is applied to these selected candidates to rank them.
In this blog, we will demonstrate how we designed a complete movie recommendation system, diving into the details of the different components that we used, like Redis, TF Serving, Feast, and FastAPI. We will not delve into model building and training. You can check out this post, where we describe how we built the retrieval model of this system.
The architecture
Modern systems often comprise multiple components or services, and this architecture is particularly well-suited for recommendation systems and machine learning (ML) models, especially when they involve multiple steps of processing.
In our case, the inference request [1] will be handled by the FastAPI ML Controller, which will then retrieve a list of candidates by calling a set of retrieval models or candidate generators [2]. Here, we generate candidates from 2 sources: a TFRS retrieval model, and by looking up the closest embeddings to the user's most liked movies in a Redis VSS instance.
After this, the controller will fetch additional metadata for the candidate movies from the Feast Feature store [3]. After getting features for these candidates, the ML Controller can choose to filter out some options based on business logic. Finally, the candidates with rich features will be passed to the Ranking model [4], which will return a ranking score for each movie to sort them.
After all of this, we can include some postprocessing logic, like boosting certain movies in the final recommendation list. This is also done in the ML Controller.
Here we dive into each component with more detail.
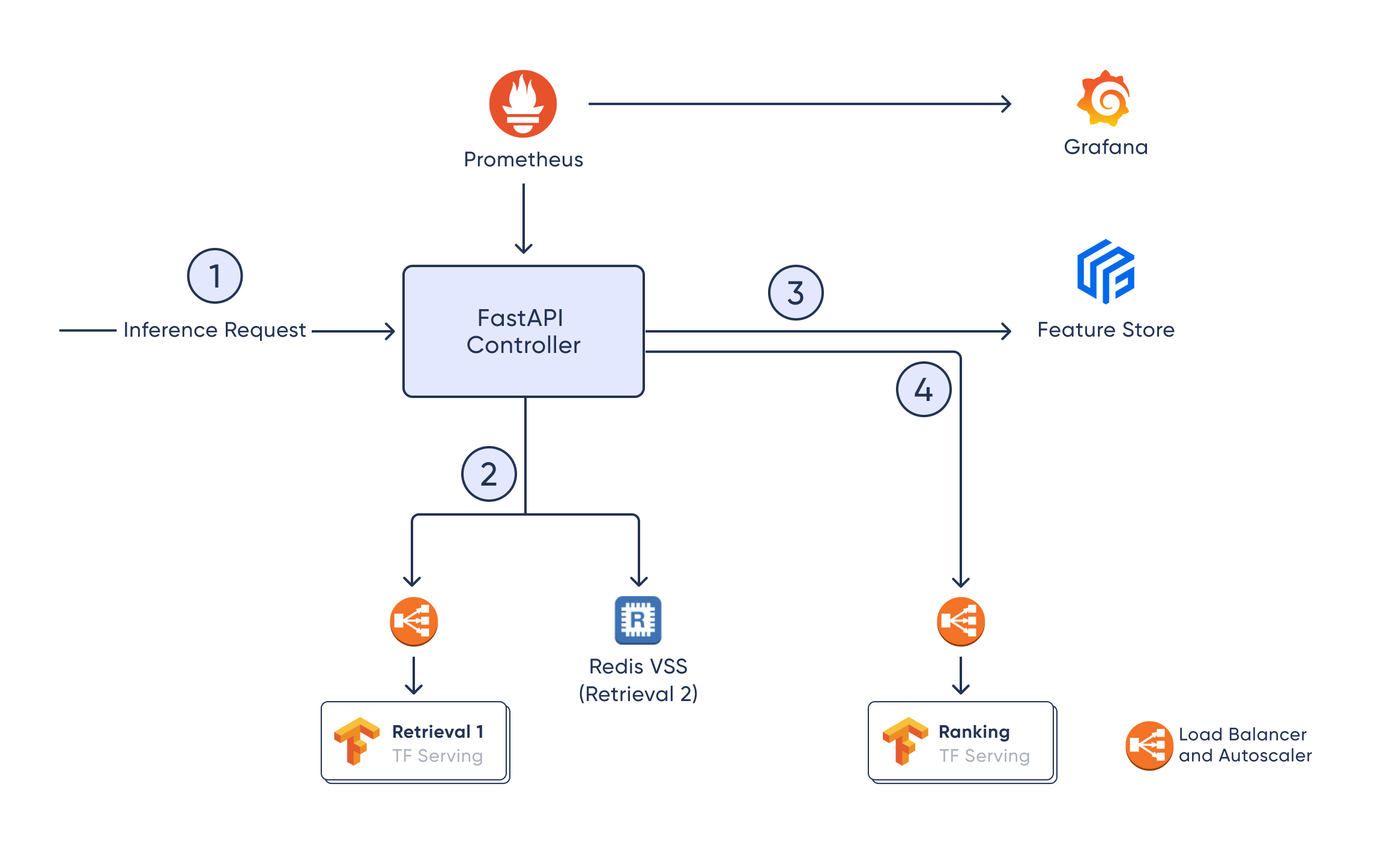
FastAPI Controller
First of all, we chose FastAPI because it’s lightweight, easy to set up, and efficient. We only need a very simple interface to our system, which is capable of doing some pre- or post-processing and then connect to the relevant services.
We designed a system that holds all the recommender-related business logic in one place (FastAPI Controller), which is separate from the main application backend. This has several advantages:
- It allows the ML Engineering team to integrate the different components of the recommendation system themselves and in Python (or their preferred language). This is especially useful when some pre- or post-processing is done in the controller.
- A separate release process will allow this component to be updated without the database migrations and related rollbacks and downtime of the main backend. Possibly the ML Controller could be released more often as well.
- Allows scaling the main backend and the ML Controller independently. You can also choose cloud instance types that better suit each of their work.
- The main backend does not need to know all the services (Redis, TF Serving, Feast) connected to the controller and must not integrate those dependencies.
The ML Controller is not only the glue that sticks the other components together; it also allows running some processing between these steps, like filtering candidates and reordering the final results taking into account some business logic or restrictions. One such restriction could be, for example, that there should never be more than 3 movies of the same genre in the top 5. This setup allows complete flexibility to implement any restriction or custom sorting rules.
Retrieval models
Retrieval models serve the purpose of candidate generation. This has to be done with quick and efficient models to take the entire catalog of options down to a few thousand or hundreds. A recommendation system might have multiple sources from where it draws its candidates, like in this case, where we deploy 2 such generators.
You can read more about the TF Recommenders Retrieval model we built in this blog post. It follows the two tower architecture, which means that item (aka movie) embeddings can be indexed during training, and the model only needs to compute query (aka user) embeddings during inference time to then find close item embeddings for them.
We supplement the candidates from the TFRS model by adding movies that are similar to the ones the user liked most. We do this by having a vector search index stored in Redis. The embeddings we use are from the OpenAI API, and you can read more about them in the same blog about the TFRS model.
Ranking model
The Ranking model tends to be heavier and slower than the retrieval models, but it only needs to run on a reduced set of candidates, which will be processed in batch. The objective of this model is to score each candidate so that they can be ordered the best way possible.
As these models might be slower, it can be crucial to set up an autoscaler and a load balancer to be able to cope with peaks in demand while not overspending during calmer moments. This also applies to the retrieval TFRS model, but in our case, the ranking model’s inference time was around 10-20x higher than that of the retrieval model, so it’s more important for this model.
Feature Store
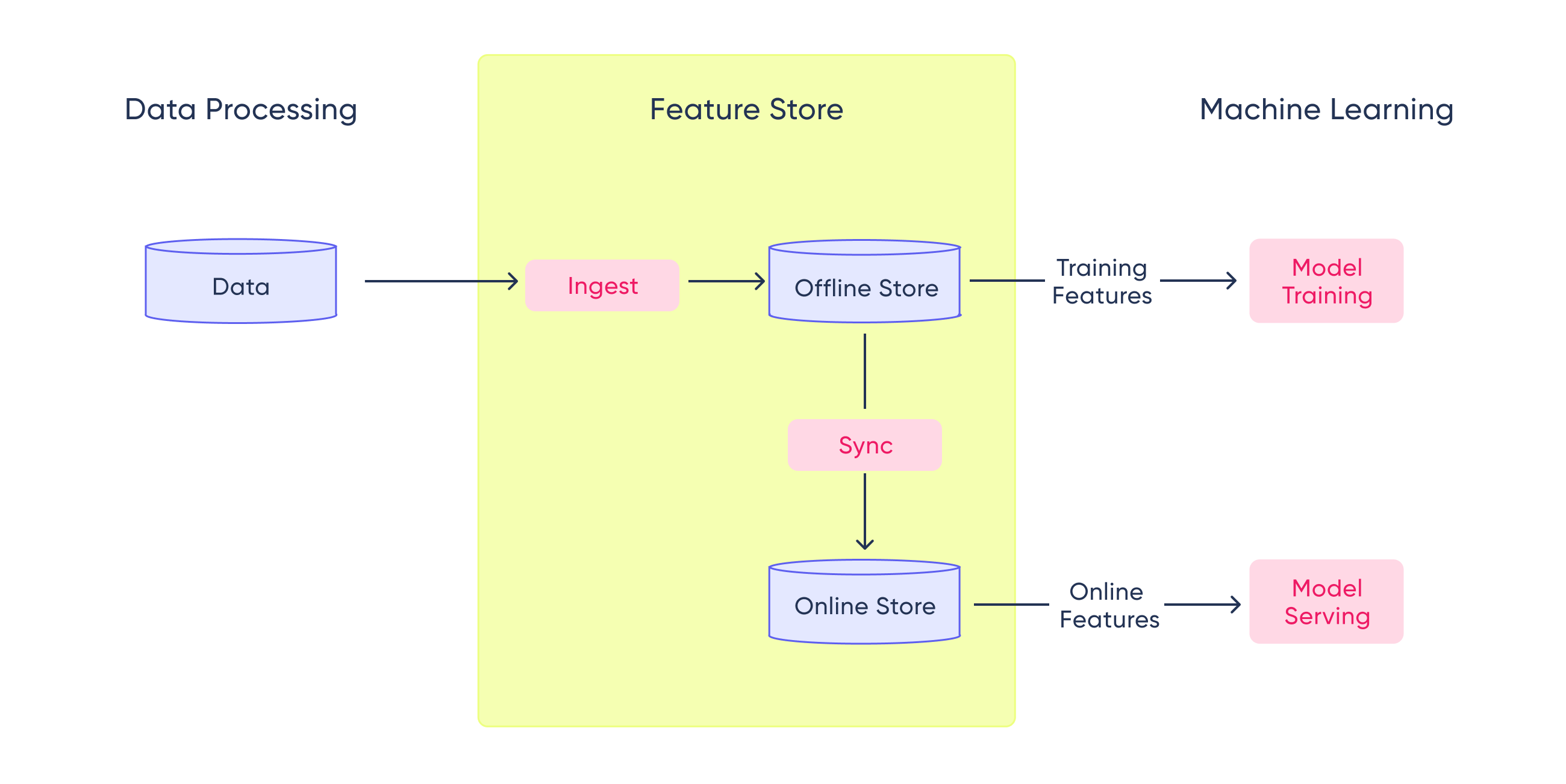
A key component of every Machine Learning project is the feature store. A feature store is a centralized repository where you standardize the definition, storage, and access of features for training and serving. It helps to have data consistency, making sure that every member of the team has the same features to train or run inference.
A feature store is usually divided into two different parts: the offline store and the online store.
The offline store is the one used to generate training and experimentation datasets. It will have timestamped historical data to be able to reproduce every experiment run during the development process.
On the other hand, the online store will have only the latest features available, which were used to train the last deployed model. This single point of contact with the features will allow ML Engineers to run models in different environments using the exact same set of features with the same columns, data types, ranges, and sizes.
Commonly, offline stores use columnar formats to improve read timings of large amounts of data. This is why Redshift, BigQuery, Snowflake, and other data warehouses are used to store historical data.
As explained before, online stores usually have only the last available data points, and since they are used for inference, they need to be fast. That is why low-latency databases such as Redis, DynamoDB, Bigtable, and Cassandra are used for this component.
In this project, we went with Feast because it's open-source and quite a popular tool. Another popular alternative in the industry is to build a custom feature store tailored to the needs of a specific team or project. This stems from the fact that most widespread solutions are not perfectly suited to every need. We used Redis for the online store, as it has quick response times, and we already had a Redis instance set up. We went with AWS S3 for offline storage because it’s cheap and a good fit for projects hosted in AWS.
We found it crucial to properly manage connections to the online and offline feature store in an abstracted singleton manager to obtain good response times and avoid Feast having to access the offline store too often (which would slow the whole process down considerably).
Monitoring with Prometheus and Grafana
Model monitoring is essential when deploying an ML system. The work of an ML Engineer actually only starts once a model or system has been deployed.
In this case, we went with Prometheus and Grafana as 2 very commonly used open-source tools. Prometheus will poll an endpoint in the FastAPI Controller at certain fixed intervals to read metrics that should be monitored. These metrics will then be aggregated by time ranges and displayed in several Grafana dashboards. We dive deeper into why we chose them and how we set up model monitoring in this other blog post.
Conclusions
In today's competitive business landscape, capturing and retaining the attention of target audiences is essential for success. That's where recommendation systems come in, offering a game-changing solution that revolutionizes customer engagement.
By leveraging cutting-edge algorithms and data analytics, recommendation systems empower businesses to deliver personalized experiences, enhance customer satisfaction, and drive revenue growth. From suggesting products to curating content, recommendation systems have become indispensable tools across industries.
If you're looking to harness the power of recommendation systems for your business, our team is here to help. Contact us today, and let us assist you in building a tailored recommendation system that will propel your business to new heights.

