


Have you ever wanted to run a neural network model on iOS and found out that it runs too slow for your use case? We faced this problem and have gone through several options to reduce model inference time. We found out that CoreML or TFlite are not always the best options performance-wise, but that in some cases, using MetalPerformanceShaders (MPS) or Bender is the way to go.
In this post, we'll go through the journey of choosing a framework, showing performance comparisons, and, hopefully helping you decide which one to use.
Running style transfer on realtime video in iOS
A few years ago, before the release of CoreML and TFlite on iOS, we built DreamSnap, an app that runs style transfer on camera input in real-time and lets users take stylized photos or videos. We decided we wanted to update the app with newer models and found a Magenta model hosted on TFHub and available for download as TFlite or TensorFlow model. Magenta is a machine learning research project from Google focused on art and music. They have published several trained models with open-source training code. The magenta repo also includes source code to retrain the model with different hyperparameters.
Running TFlite on iOS
We wanted to measure how fast it was, so we took the float16 version of the TFlite model and ran it on an iPhone 12. Running on CPU only, the model takes 360ms to process a 384x384 image, translating to less than 3 FPS. We tried to use the Metal or CoreML delegates to run this model on the GPU, but the TFlite Interpreter failed to build the model for the GPU, which meant the best we could get out of the TFlite model was 3 FPS.
Note: in this post, we did not consider MLKit, but its performance should be similar to using TFlite directly.
Converting to CoreML
Converting a TFlite model to CoreML is not easy. Also, the base TF model available on TFHub, was not exactly the same as the TFlite model, so we had to retrain it. Luckily the source code to train it's available, and we proceeded to train a model with the same architecture as the TFlite model. Then, we converted it to CoreML using coremltools and tested it on the same iPhone 12. For this model, we processed a 384x768 image, which allows using the iPhone full screen in portrait mode and duplicates the image to process. Increasing the image size will roughly increase the processing time by the same factor, which you need to consider when comparing different models.
CoreML chooses on which device (CPU, GPU, or Neural Engine) your model will run. However, it allows you to limit which devices it can choose:
- CPU only
- CPU and GPU
- all (Neural Engine, CPU and GPU)
As you might have noticed, the CPU option will always be enabled, meaning CoreML can always choose to run your model on CPU (which normally has the worst performance compared to GPU and NE).
Running the CoreML on CPU only or CPU and GPU gave similar results between 4-5 FPS (210-240ms). However, when using all devices, we were able to achieve 16 FPS, getting closer to our objective of running video processing in real-time.
It was strange to us why the CPU and GPU option didn't outperform the CPU only option, actually being a little bit slower.
Using the GPU Frame Capture from Xcode we debugged the model when running with GPU and found that CoreML would just run small parts of the neural network graph on the GPU and the rest on CPU, so that the cost of moving memory to the GPU and back is likely the reason why using GPU and CPU is slower than CPU only.
But we weren't satisfied with the result we got from CoreML, so we decided to use the MetalPerformanceShaders framework to, hopefully, improve the FPS. Using MPS directly can be a bit tedious because of how the API is set up, which is why, in 2017, we developed Bender to facilitate this process both for us and the community. The introduction of the MPSNNGraph made using MPS a bit easier but didn't solve all of its problems.
About Bender
Bender was the result of abstracting and generalizing the code we developed for DreamSnap. It's an abstraction built above MPS with some additions. One of its main advantages is that it allows converting TensorFlow frozen graphs to its own graph representation, wrapping MPS or custom layers. This conversion is not always trivial and requires a lot of reading documentation and testing.
If you were to use only MPS, then you would need to rebuild the NN graph using MPS layers, copy and transform each layer's weights to the expected format, and store them in a way you can load them correctly for each layer.
Bender's TFConverter solves all of this.
The drawback is that Bender supports a limited subset of layers, so if you want to use it for other models, chances are you will need to add support for extra layers.
Bender vs CoreML vs TFlite
We haven't been maintaining Bender a lot since CoreML was released. However, we figured it was still worth a shot. We had to add support for a few new layers, but then running the model was straightforward. And to our surprise, we were able to almost double the FPS we got from CoreML, achieving over 30 FPS. This improvement is possible because Bender uses only the GPU and therefore will run much quicker than running most parts on CPU.
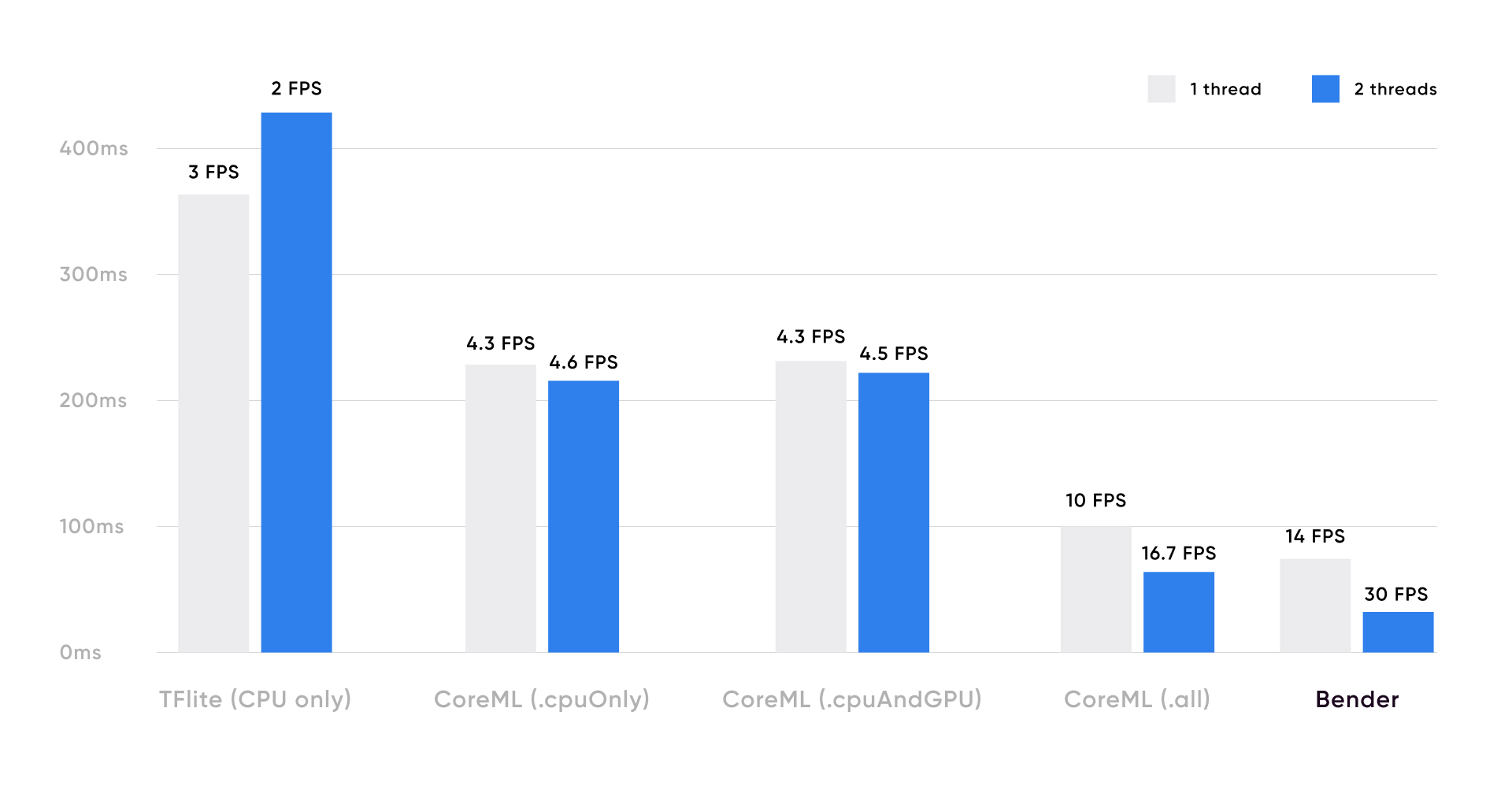
This table shows the performance comparison running each framework using 1 or 2 concurrent threads, processing 384x768 images on iPhone 12 (the TFlite model was run on 384x384 images). There doesn't seem to be a big advantage for using multiple threads on models that run mainly on CPU.
However, there's a catch.
Using the GPU is more expensive battery-wise for the iPhones.
The energy impact of using MPS or Bender compared to CoreML when using the .all option is considerable.
So, depending on your use case and how much time you expect your model to run, you will have to prioritize either performance or battery.
Note, however, that when using CoreML's .cpuAndGPU option, the energy impact is similar to when you use Bender, but the performance is way behind.
We could also state from the results of this experiment, that the main advantage of the Neural Engine is for the device's battery, not for the performance of the models.
So which framework should I choose?
The short answer to this question is: It depends.
First of all, it depends on your needs. If your model doesn't need to run in real-time or only run it on single images (or a small number), then you don't need 30 FPS performance. CoreML and TFlite are easy to use, with just a few lines of code you can get your model running. And there are lots of examples. So it's quick and easy to see what you can get out of them for your model. If their performance is good enough, stay there; you might want to invest your time in other tasks. Moreover, Apple and Google maintain these frameworks, so you should get decent support and, hopefully, further improvements for these frameworks.
If you need real-time performance and both TFlite or CoreML aren't cutting it, then the moment to consider using MPS (either directly or with the MPSNNGraph) or Bender has come.
So you should use CoreML or TFlite when:
- You want to quickly try a model
- You don't need real-time performance
- You expect your model to be running during a prolonged period of time, and you want to avoid draining the user's battery
- The performance is good enough for your use case
However, consider using MPS or Bender when:
- The performance of CoreML is not good enough
- You want to make sure that your model runs on the GPU
It must be said as well that:
- The difference shown for this model won't always be the same for other models
- CoreML could choose to run bigger parts of the network on GPU or NE and thus run faster
- The network architecture will likely be an important factor here
- For certain architectures, using MPS means the speedup will increase, whereas, for others, you might not get any benefit
To sum up
CoreML and TFlite are easy-to-use frameworks, but may not be the best options if you need real-time video processing. That's when MPS or Bender come in to help with increased performance, albeit with greater battery use.
Bender allows converting frozen TF models and running them in iOS, although, this process might not be straightforward. If you need help doing such a conversion, feel free to reach out at [email protected].

