


It's been over a year since Apple has introduced Create ML, a framework that allows you to build neural network models in Swift and use them on iPhones and iPads with Core ML. However, the most common way of getting a CoreML model is still by converting a model trained on TensorFlow, Keras, Pytorch or other ML frameworks. Apple officially supports coremltools which allows converting some model formats like Keras, Caffe (v1) and TensorFlow (since version 3.0).
Unfortunately, not all model formats can be converted so easily to Core ML. For example, there is no library that supports converting a TensorFlow Lite model. While this is not required when you train your own model in TensorFlow, it can be helpful if you want to do performance comparisons between different on-device frameworks, or if you want to run a recently published research model in CoreML and you only have the model in TF Lite format.
TensorFlow Lite is used to deploy TensorFlow models on mobile or embedded devices but not for training them. Once converted to TF Lite, a model cannot be converted back to a TensorFlow model but we can inspect its architecture and export its weights in order to reimplement the network graph in TensorFlow. We can then use coremltools or tfcoreml to convert it to CoreML. This is what we are going to accomplish in this tutorial.
We will use an MNIST model from the TF Lite examples repository. MNIST is a handwritten digit database. So the task this model tries to perform is to recognize handwritten digits, which can be done fairly well with a relatively small model.
So for example, for the following image, we want our model to predict "0":

Inspecting the model
The first thing we should do is to inspect the model to see its layers. One great tool to do this is Netron. With Netron you can see the model's graph and even export its weights. With the MNIST model we get the following:
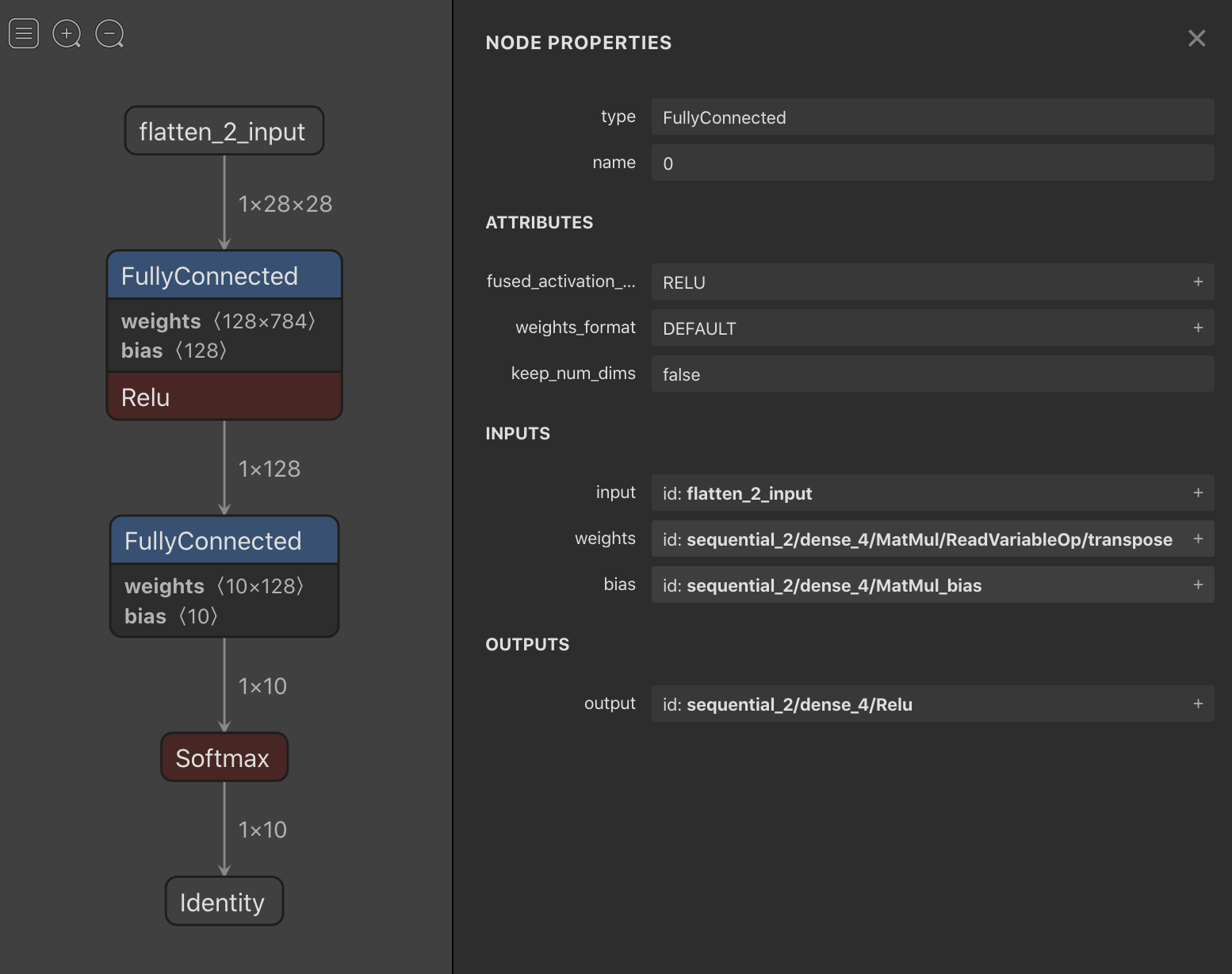
There we can see that this simple model has the following layers:
- A Flatten layer which serves as input
- A FullyConnected, or Dense, layer with ReLU activation function
- Another FullyConnected layer without activation function
- A Softmax layer
We can also print each node in the graph of the model using the following snippet:
import tensorflow as tf
# Load TFLite model and allocate tensors.
interpreter = tf.lite.Interpreter(model_path="mnist.tflite")
interpreter.allocate_tensors()
# Get tensor details.
details = interpreter.get_tensor_details()
for detail in details:
print(detail['index'], detail['name'], detail['shape'])Using this snippet we get the following output for our model:
0 Identity [ 1 10]
1 flatten_2_input [ 1 28 28]
2 sequential_2/dense_4/MatMul/ReadVariableOp/transpose [128 784]
3 sequential_2/dense_4/MatMul_bias [128]
4 sequential_2/dense_4/Relu [ 1 128]
5 sequential_2/dense_5/BiasAdd [ 1 10]
6 sequential_2/dense_5/MatMul/ReadVariableOp/transpose [ 10 128]
7 sequential_2/dense_5/MatMul_bias [10]Exporting the weights
As said before, Netron also allows us to export the weights of these layers. However, on this guide, we are going to export them differently.
To export the weights we are going to use the get_tensor function of the tf.lite.Interpreter. This function cannot be used to get intermediate results of a graph but it can be used to get parameters such as weights and biases as well as the outputs of the model.
Using the code snippet in the previous section we get the indexes of the parameters we have to export. We can now create a function to extract them from the interpreter:
def get_variable(interpreter, index, transposed=False):
var = interpreter.get_tensor(index)
if transposed:
var = np.transpose(var, (1, 0))
return varFully connected weights must be transposed. That might also be necessary for convolution weights, for example.
Building the model
We have to reimplement the model in TensorFlow, unless we have the code that produced the model. In our case, it is a pretty simple model that we can rebuild easily. First, we will implement the dense layer (which we will use later):
def dense(params):
X, W, b = params
return tf.add(tf.matmul(X, W), b)We use only one parameter to be able to use this function in a
Lambdalayer
And now we build our model (using TF 2):
import tensorflow as tf
from tensorflow.python.keras.layers import Lambda
# ...
def network(input_shape, interpreter):
W1 = get_variable(interpreter, 2, transposed=True)
b1 = get_variable(interpreter, 3)
W2 = get_variable(interpreter, 6, transposed=True)
b2 = get_variable(interpreter, 7)
inputs = tf.keras.layers.Input(shape=input_shape)
# Flatten layer
x_0 = tf.keras.layers.Flatten()(inputs)
# First fully connected with relu
x_1 = Lambda(dense)((x_0, W1, b1))
x_1relu = tf.nn.relu(x_1)
# second fully connected
x_2 = Lambda(dense)((x_1relu, W2, b2))
# Finally the softmax
x_softmax = tf.keras.activations.softmax(x_2)
return tf.keras.models.Model(inputs=inputs, outputs=[x_softmax])Testing and Debugging your Model
At this point we should test that our model gives the same output as the original so that we know our implementation is correct. Constructing the same model as the one used in the TF Lite model is not always straightforward.
Sometimes you won't know why your implementation does not return the same result as the original, and it is not easy to debug errors in this context. For such cases it is helpful to check layer by layer that your model gives the same output as the original to know where to search for the bug. Getting intermediate outputs from a TensorFlow model is not difficult: you only need to return said node as an output of the model.
The same does not happen to a TFLite model. You can't get intermediate outputs using the get_tensor() method.
What I used to debug the model and get to a working version is this tflite_tensor_outputter script.
This script will generate a folder with details and outputs of each intermediate node in the graph by changing the output node index in the graph.
You can use it like this:
python tflite_tensor_outputter.py --image input/dog.jpg \
--model_file mnist.tflite \
--label_file labels.txt \
--output_dir output/Converting the model
We now have the model but we still need to convert it.
We will use tfcoreml to convert our TensorFlow model.
The convert method supports a path to a SavedModel but only when specifying a minimum iOS target of '13'.
Nevertheless, it did not work for me using SavedModel so I had to freeze the TensorFlow graph and then convert it.
Freeze the graph
To freeze a model you can use the freeze_graph utility from tensorflow.python.tools, but again it did not work for this model.
You can also freeze the model using the following snippet:
# imports ...
FROZEN_MODEL_FILE = 'frozen_model.pb'
# Taken from https://stackoverflow.com/a/52823701/4708657
def freeze_graph(graph, session, output):
with graph.as_default():
graphdef_inf = tf.graph_util.remove_training_nodes(graph.as_graph_def())
graphdef_frozen = tf.graph_util.convert_variables_to_constants(session, graphdef_inf, output)
graph_io.write_graph(graphdef_frozen, ".", FROZEN_MODEL_FILE, as_text=False)
# Load TFLite model and allocate tensors.
interpreter = tf.lite.Interpreter(model_path="mnist.tflite")
interpreter.allocate_tensors()
input_shape = [28, 28, 1]
model = network(input_shape, interpreter)
# FREEZE GRAPH
session = tf.keras.backend.get_session()
INPUT_NODE = model.inputs[0].op.name
OUTPUT_NODE = model.outputs[0].op.name
freeze_graph(session.graph, session, [out.op.name for out in model.outputs])The output is a frozen .pb file which we can finally convert to CoreML
Note: Both the snippet above and the one below must be run on TensorFlow 1.x (1.14 in my case)
tf_converter.convert(tf_model_path=FROZEN_MODEL_FILE,
mlmodel_path=OUTPUT_FILE,
output_feature_names=['Softmax:0'],
input_name_shape_dict={'input_1:0': [1, 28, 28, 1]},
image_input_names=['input_1:0'],
image_scale=1.0/255.0,
class_labels=["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"])And that is it. We have a CoreML model!

Conclusion
Some takeaways from this post:
- TensorFlow Lite models have to be converted manually to CoreML but that can be done, specially when you already have some code that produces the same architecture.
- Converting a model to CoreML can be tricky in some cases.
- Sometimes you must use a different layer or function for the conversion to be successful.
The source code used in this tutorial can be found in this GitHub gist.
Need help with ML tasks like converting models to CoreML? We're glad to help! Get in touch at [email protected]
We have also written other posts about ML topics. Is your CoreML or TFlite model not fast enough on iOS? Check out our post about speeding up performance on iOS with MPS and Bender.
And if you'd like to know 5 Practical Ways to Speed Up your Deep Learning Model check it out here.

