

Machine Learning
From Low to High-Quality Image — Practical Application of Super-Resolution Algorithms

Nowadays, everyone is exposed to artificial intelligence (AI) in one way or another. Computer vision is a popular application of AI through cellphones, video conference platforms, and video vigilance cameras, among other use cases. One fascinating problem to solve within the computer vision field is super-resolution (SR).
There are two different approaches: the academic and the "practical" approach. The difference between them is time frames. Because academic work involves a lot of validation and later publishing of the algorithms, it can take several years. However, the industry can't wait that much time due to the constant change in its landscape. Practical applications of SR problems, need to make sense of academic data, pipelines and features transformation.
This blog aims to compare different state-of-the-art algorithms for SR and their application in the industry, stating if the academic work is actually reproducible for practical use.
What is Super-Resolution and how does it work?
Super-resolution aims to extract a High-Resolution (HR) image from its respective Low-Resolution (LR) one. Another idea behind SR is to find patterns and tendencies from the HR images and reconstruct the image in LR, something like an inverse solution.
There are two approaches to solve the super-resolution problem:
- The classic approach: uses statistical methods, prediction-based methods, and sparse representation methods to achieve super-resolution.
- The Deep Learning (DL) approach: the most common method.
The algorithms are based on Convolutional Neural Network (CNN) and Generative Adversarial Network (GAN). Reinforcement Learning algorithms have been used recently. The transformer concept is also widely applied to NLP problems, such as RCAN, ESRGAN, SRFBN, RDN, and SwinIR.
The metrics used for measuring image quality are vital. Although there are several metrics, we selected those with no implicit human subjectivity. Plus, these metrics were all in the academic paper we based our research on.
Image Quality Metrics
Peak signal-to-noise ratio (PSNR): It's a qualitative measure of image quality compression, defined by the maximum pixel value and the mean square error between the reference image and the SR image, also known as the power of image distortion noise. A disadvantage of this method is that it doesn't consider the structural informa6tion within the image.
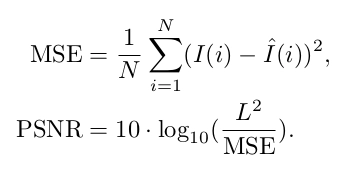
Structural similarity index (SSIM): This metric compares the reference image's contrast, luminescence, and structural details with the reference image. This method is unstable in cases where the variance or luminescence of the reference image is low; therefore, in medical imaging, for example, this metric could have inconsistent results.
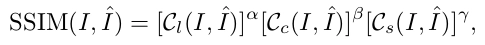
Structures and description of SR algorithms
Choosing the algorithms
The source for the algorithms is the Paperwithcode. It was chosen because it allows us to see the results obtained with the author's conditions plus, it provides a git repository with code (such as a Notebook) ready for reproducing the experiments in our environment (for example, Google Colab). These features, allowed us to test the algorithms in our images and draw some conclusions.
The idea behind super-resolution algorithms
The general idea behind all algorithms is an extensive neural network with the objective of learning high-frequency information and several blocks of neural networks that learn low-frequency information. That information processing method allows for better performance, even when the number of blocks increases. The role of blocks is to avoid wasting time with low-frequency info and use this knowledge in the next block.
Our selected algorithms explained
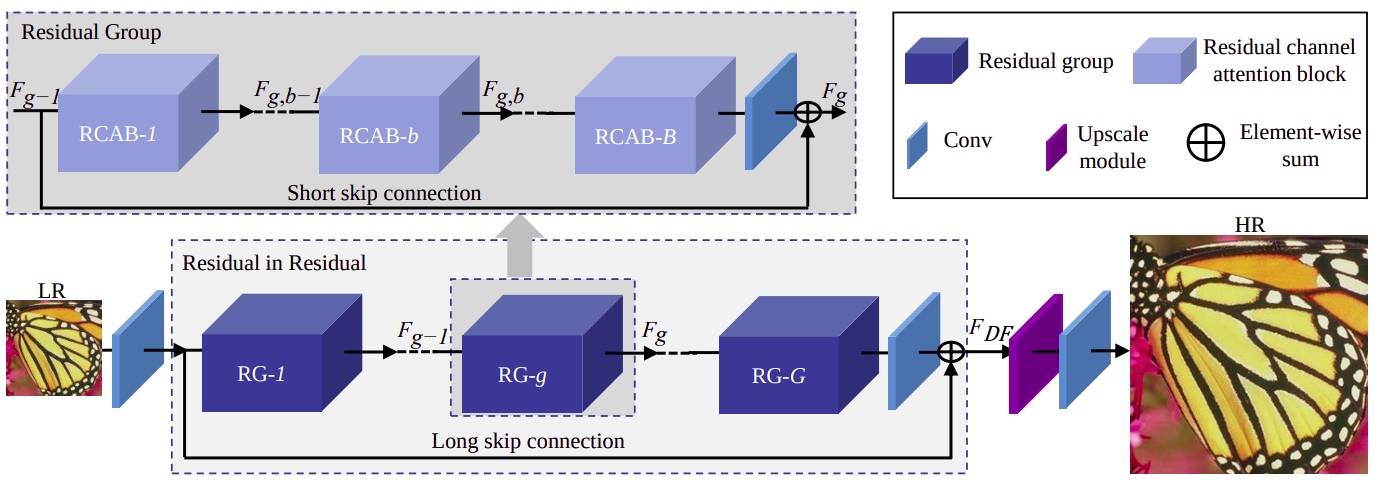
RCAN: This paper's authors propose deep residual channel attention networks (RCAN). Specifically, they present a residual in residual (RIR) structure to form a deep network consisting of several residual groups with long skip connections. Each residual group contains some residual blocks with short skip connections. Meanwhile, RIR allows an abundance of low-frequency information to be bypassed through multiple skip connections, making high-frequency learning the main network focus. Furthermore, they propose a channel attention mechanism to rescale channel-wise features by adapting interdependencies among channels.
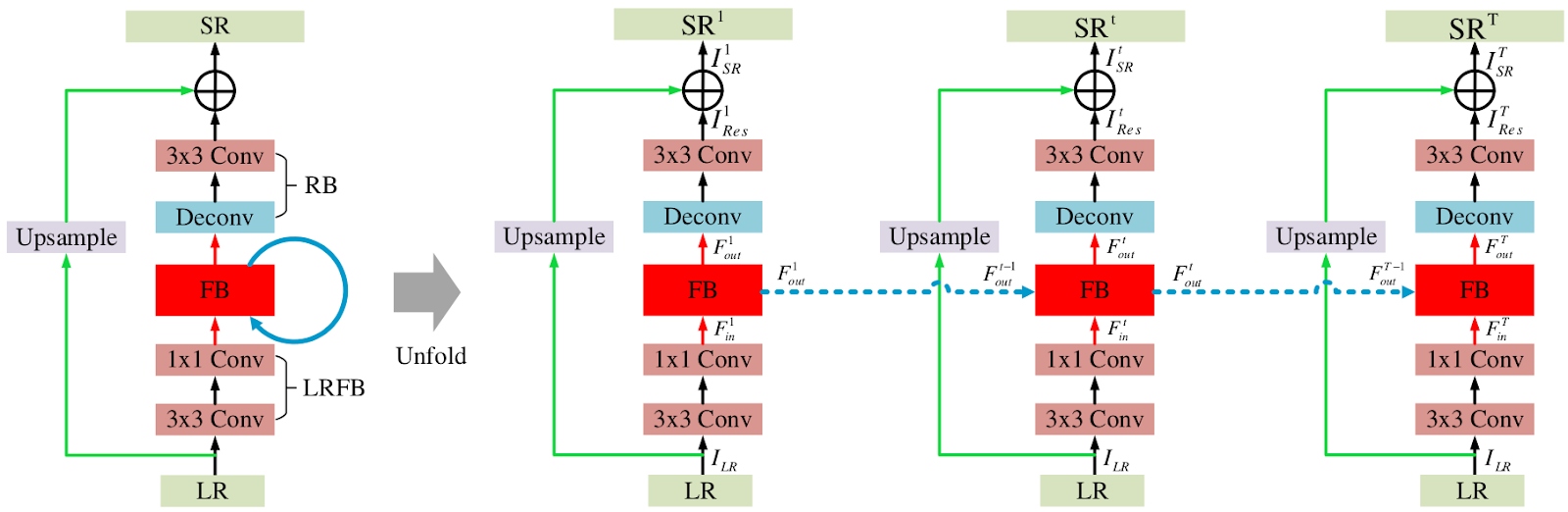
SRFBN: In this paper, the authors put forward an image super-resolution feedback network (SRFBN) to refine low-level representations with high-level information. Specifically, they use hidden states in an RNN with constraints to achieve such feedback. A feedback block is designed to handle the feedback connections and to generate powerful high-level representations. The proposed SRFBN has a strong early reconstruction ability and can create the final high-resolution image step by step. In addition, they introduce a curriculum learning strategy to make the network well suitable for more complicated tasks, where multiple types of degradation corrupt the low-resolution images.
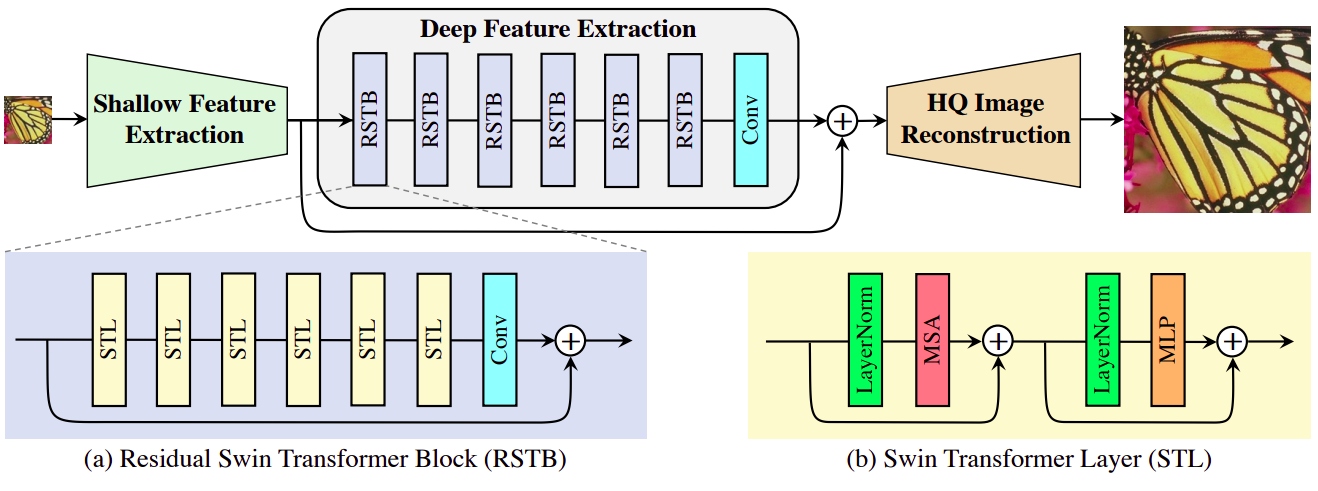
SwinIR: While state-of-the-art image restoration methods are based on convolutional neural networks, few attempts have been made with Transformers, which show impressive performance on high-level vision tasks. This paper proposes a robust baseline model SwinIR for image restoration based on the Swin Transformer. SwinIR consists of shallow feature extraction, deep feature extraction, and high-quality image reconstruction. In particular, the deep feature extraction module comprises several residual Swin Transformer blocks (RSTB), each of which has several Swin Transformer layers together with a residual connection.
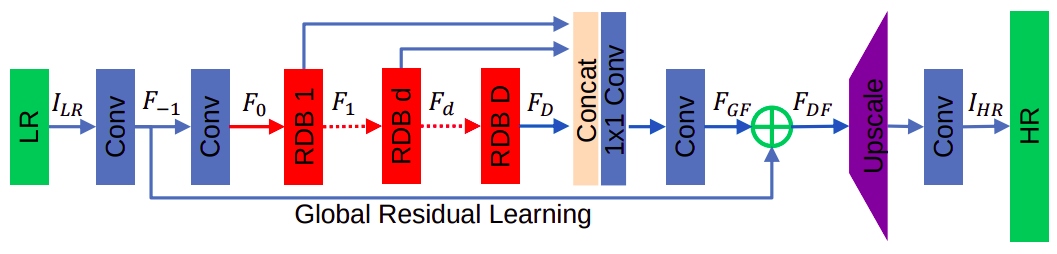
RDN: In this paper, the authors propose a novel residual dense network (RDN) to address the image SR problem. They fully exploit the hierarchical features from all the convolutional layers. Specifically, they propose residual dense block (RDB) to extract abundant local features via densely connected convolutional layers. RDB further allows direct connections from preceding RDB to all the layers of current RDB, leading to a contiguous memory (CM) mechanism. Local feature fusion in RDB is then used to adaptively learn more effective features from preceding and current local features and stabilize the more comprehensive network's training. After fully obtaining dense local features, we use global feature fusion to jointly and adaptively learn global hierarchical features holistically.
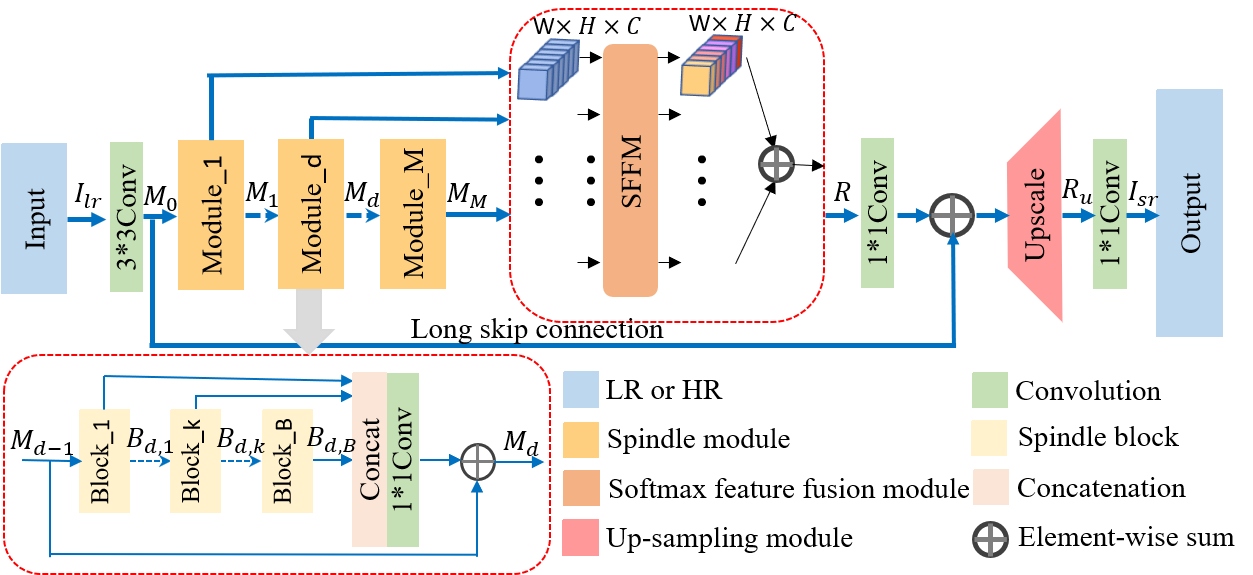
LFFN: The authors of this paper propose a lightweight feature fusion network (LFFN) that can fully explore multi-scale contextual information and significantly reduce network parameters while maximizing SISR results. LFFN is built on spindle blocks and a softmax feature fusion module (SFFM). A spindle block is composed of a dimension extension unit, a feature exploration unit, and a feature refinement unit. The dimension extension layer expands low dimension to high dimension and implicitly learns the feature maps suitable for the next unit. The feature exploration unit performs linear and nonlinear feature exploration aimed at different feature maps. The feature refinement layer is used to fuse and refine features. SFFM combines features from other modules in a self-adaptive learning manner with softmax function, making full use of hierarchical information with a small amount of parameter cost.
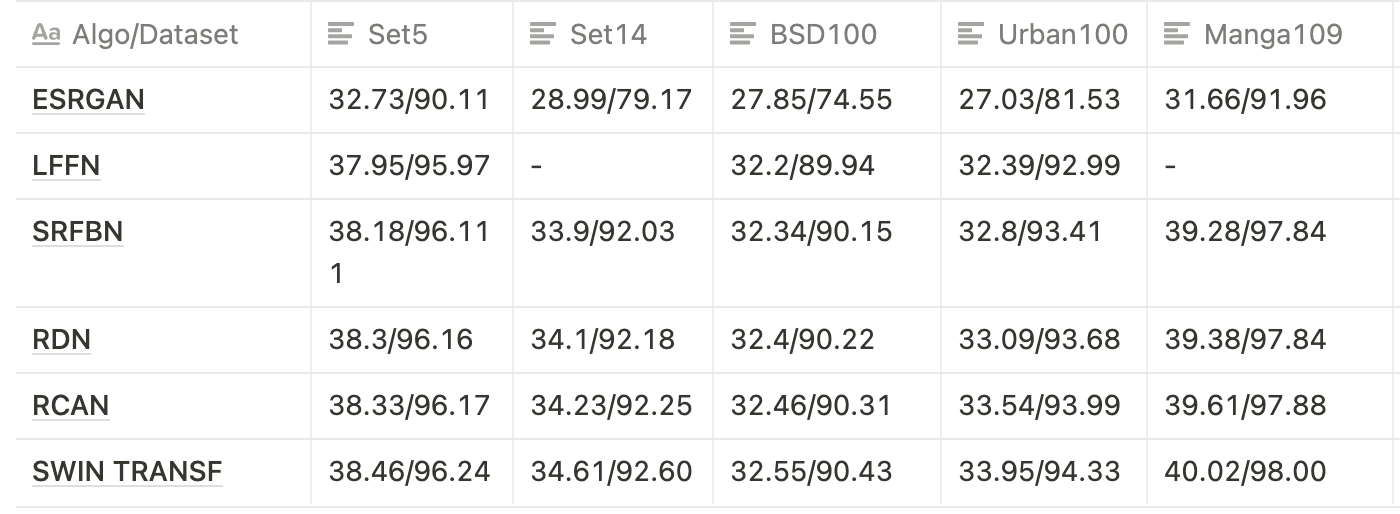
Quantitative Analysis (PNSR/SSIM):
After a recap of the algorithms’ main components, we started with quantitative results. We use datasets Set5, Set14, BSD100, Urban100, and Manga109. The results of algorithms based on GAN were generally worse than the rest, and SwinIR was the best of them all. This analysis is only concerning selected metrics. We didn't consider aspects such as training time or hardware used because there isn't any information about that in the papers we mentioned.
Our analysis and tests
Our algorithms review aims to prove whether we can obtain academic results if we apply them to the set of images we selected and use those algorithms in computers with no GPU.
Quantitative results
Our results were similar to those academic papers that used the same datasets. So, we decided to take two of them and compare them. We ran RCAN and SwinIR and got GPU (NVIDIA® Tesla® K80) and CPU (Intel corei7) to predict time with our images. The pictures we used for testing have different categories: cities, interiors, exteriors, faces, and people. They also have several sizes and qualities: 1024x720 (HD and LD), 800x600 (HD and LD), 500x700 (LD).
Our quality criteria for the original images in RCAN and SwinIR was the following:
- 4-High
- 3-Medium
- 2-Low
- 1 -Horrible
| RCAN time GPU | SwinIR time GPU | Res_original | Quality evaluation |
|---|---|---|---|
| 17.24s | 31s | 160x160(LD) | 2 |
| 19.01s | 53s | 492x712(LD) | 3.3 |
| 22.48s | 58s | 497x712(LD) | 3.7 |
| 16.63s | 41s | 500x400(HD) | 4 |
| 16.86s | 49s | 800x400(MD) | 4 |
| 56.22s | 1m | 800x600(HD) | 4 |
| 36.49s | 1m | 1024x683(HD) | 4 |
| 36.49s | 1m | 1024x683(HD) | 4 |
| 30.55s | 1m | 1024x720(HD) | 3.6 |
| 36.83s | 1m | 1024x720(HD) | 4 |
| 52s | 1024x720(HD) | 4 | |
| 51.50s | 1m | 1024x720(LD) | 3.3 |
| 51.01s | 1m | 1024x720(LD) | 2 |
After seeing similar results of academic papers, we can conclude that almost all algorithms have identical numerical results. However, SwinIR is slightly better. Regarding the predicted time, it's better in GPU, but we need to keep in mind that we can't use this algorithm in real-time applications. The mean time for RCAN was 30 seconds and 54 seconds for SwinIR, depending on the size and quality of the image.
Qualitative results and use cases
In the next section, we'll discuss qualitative results. Here we'll have different perspectives and several examples about how SwinIR is better in some cases, but RCAN has advantages for others.


For this image, SwinIR was better at eliminating the noise around the flower's petals and made a reasonably good reconstruction of the light in the fruit even after zooming.


Here SwinIR did an excellent job with lines and recovering the texture of the stones in the floor and wall. The reconstruction of the shadows was really "meticulous," preserving its topology, meaning that despite correcting the image, the algorithm maintains the lounge chair's geometric proportions (shape, size, etc.)


There is no question that SwinIR was the top performer in the above cases. However, things take a turn in the images we'll see below.
In the marketing industry, it's common to see images that focus on one object while the background is blurred or out of focus. For this type of image, SwinIR isn't the best alternative because its algorithm is based on reconstructing the image, so it will try to "fix" the background blur that's there intentionally. Let's see some examples:


In this image, Muhammad Ali's fist is in focus while the rest of his body is blurred. When we apply SwinIR, it tries to repair this effect, ignoring the intention behind the picture. We can mitigate this error by using SwinIR in the fist and then RCAN in the rest of the image.
The next question is: Can we find some image that improves its quality and keeps the sense and topology through SwinIR? Trying to answer this led to some excellent examples. Let's see them:


In this case, we can see how the algorithm considers the wheel's blurriness (due to movement) in the car behind while it improves the vehicle itself, making a distinction within the same object.
Can SwinIR keep the topology of the image in paintings like Van Gogh's The Starry Night?


To our surprise, the algorithm did an excellent job changing dark colors but nothing else.
There's a wide variety of use cases for this kind of algorithm: in medical imaging to try and amplify some sectors that need better resolution, satellite images also require you to zoom around a specific object, video vigilance cam when someone's face is blurry, etc.
Conclusion
Having run both SwinIR and RCAN on diverse images with different qualities and compositions, we can confidently state that choosing one over the other will depend on the image we’re using. Sometimes, like in Muhammad Ali's picture, using both algorithms will provide you with a more accurate result. So choose the algorithm with the use case in mind.
Furthermore, it's not always easy to reproduce the academic results we saw in the papers, but the numbers when we applied them to specific images from our computers, weren't bad either.
You should also consider the result's predicted time because, if you're looking for real-time results, these algorithms are not the answer.

